
はじめに
本文は元々社内ATAプラットフォームで公開されたものですが、データ開示審査を経て、この記事として再構成されました。そのため、記事内には多くの社内システムに関する紹介やリンクが含まれていますが、これらのリンクやプラットフォームは社内ネットワーク以外では開くことができません。しかし、記事全体の閲覧や理解には影響ありません。この記事は、Alibaba開発者プラットフォームにも同時公開されています。アドレス:経験まとめ|Alibaba.comのバイヤー向けパフォーマンス最適化をどのように行ったか
背景
なぜパフォーマンス最適化を行うのか
ほとんどのウェブサイトにとって、マクロな視点から見ると、最終的なウェブサイトのビジネス効果に影響を与える主な要因は以下の2つです。
- ユーザーの全体規模
- サイト内でのユーザーのコンバージョン率
业务效益 = 用户规模 * 转化率したがって、ビジネス効果を向上させるためには、ユーザー規模とコンバージョン率を向上させる必要があります。
ユーザー規模
ユーザーは主に新規ユーザーと既存ユーザーで構成されており、それぞれトラフィックの構成も異なります。しかし、新規ユーザーも既存ユーザーも、ユーザーのクライアント、つまりサイト外から当社のウェブサイト、つまりサイト内に到達するプロセスを経ます。
特にAlibaba.comはグローバルなウェブサイトであり、ネットワークインフラが発達した欧米から、発展途上の第三世界諸国まで、ユーザーはPCや携帯電話などのデバイスを通じて当社のウェブサイトにアクセスします。
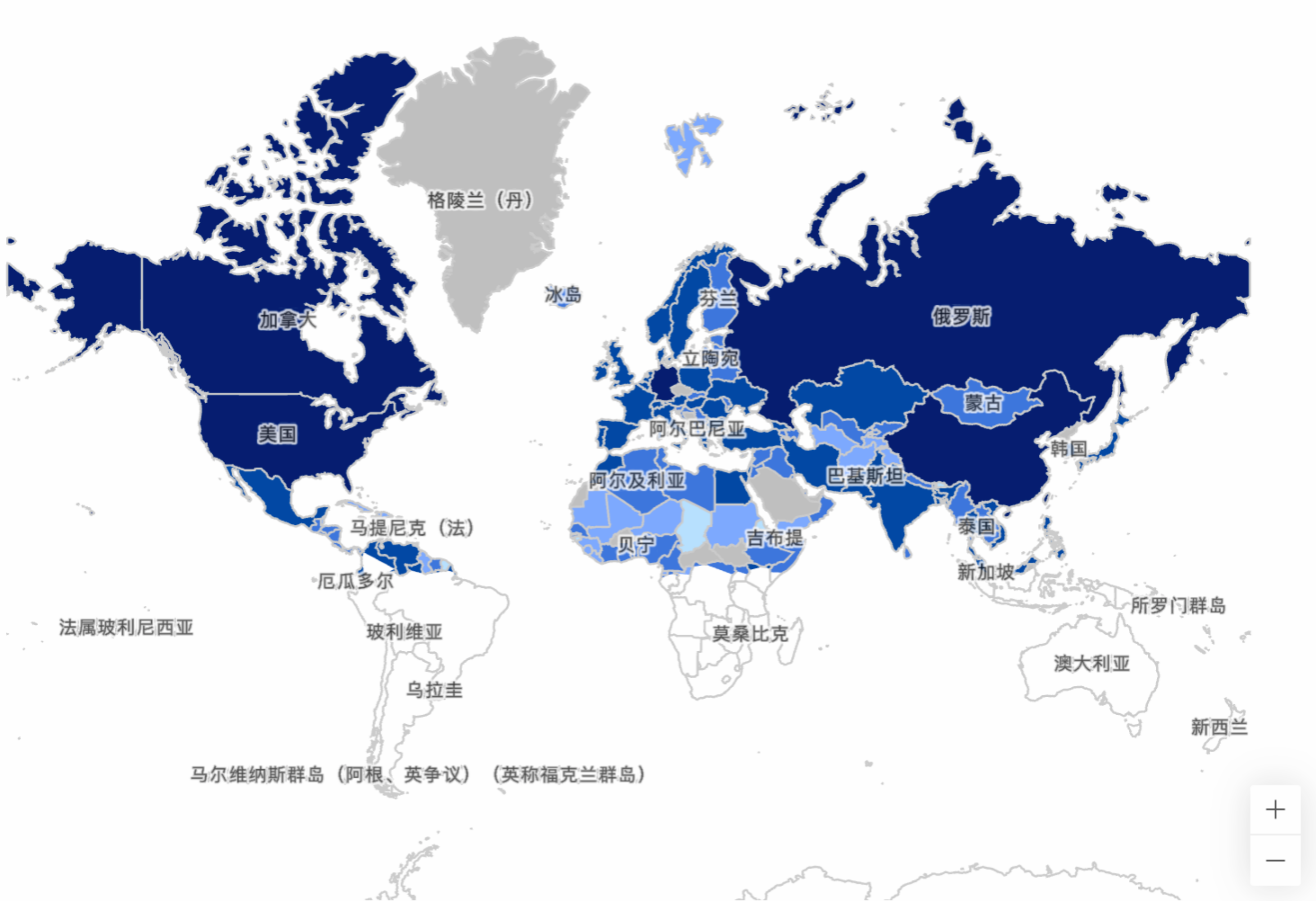 Alibaba.comのあるページのユーザー国別分布図
Alibaba.comのあるページのユーザー国別分布図
複雑なネットワーク状況や技術的現状により、ウェブページの読み込みが遅くなり、ユーザーは長い空白画面の待機に耐えられず、ウェブサイトを閉じてしまう可能性があり、ユーザーの離脱につながります。 多くの事例が、読み込みパフォーマンスがユーザー規模に与える影響を示しています。
- BBCでは、ページ読み込みに1秒追加されるごとに、ユーザーの10%が離脱することが確認されています。
- パフォーマンス向上のためにページを再構築した結果、Pinnerの待機時間が40%減少し、SEOトラフィックが15%増加し、サインアップへのコンバージョン率が15%増加しました。
したがって、ウェブサイトの読み込みパフォーマンスは、最終的にサイト内に到達するユーザー規模に直接影響します。
コンバージョン率 コンバージョン率に影響を与える要因は非常に多く、ウェブサイトが提供する価値、ユーザーの意欲、ページのユーザー体験などが重要な影響要因です。そして、ウェブサイトのインタラクションパフォーマンスは、ユーザー体験に大きな影響を与える要因の一つです。
ウェブサイトの表示中にページ要素が揺れたり、ページをスクロールする際にカクついたり、ボタンをクリックしてからユーザーの操作に反応するまでに1秒かかったりすると、ユーザー体験が著しく損なわれ、クリック率や直帰率に直接影響し、最終的にコンバージョン率に影響を与えます。
だからこそ、私たちはパフォーマンス最適化を行う必要があります。
なぜ常にパフォーマンス最適化を行うのか
定期的にパフォーマンス最適化が再提起されるのはなぜでしょうか。
- パフォーマンス劣化:ビジネスの発展と機能のイテレーションに伴い、既存のビジネスにますます多くの機能が段階的に追加され、機能の複雑さの増加もパフォーマンスの現状を徐々に悪化させます。
- 指標の進化:技術の発展とユーザーの究極の体験追求に伴い、より正確でユーザーの体感に近いパフォーマンス評価指標が提案され、使用されるようになります。古いパフォーマンス評価指標に基づいて最適化された結果が、新しい指標の下では必ずしも適切であるとは限りません。
これらの理由により、現在のページのパフォーマンスはあまり理想的ではありません。
目標
私たちはパフォーマンス最適化の目標を、バイヤー向けフロントエンドのコア閲覧経路ページがCore Web Vitalsの評価指標におけるGood Url基準を満たすこととしました。
Core Web Vitalsとは
Core Web Vitals(以下、CWV)は、Googleがページのパフォーマンスを測定するために提案した、複数の指標で構成されるページ体験評価基準のセットです。現在、主に以下の3つの指標が含まれています。LCP、FID、CLS。
- LCP: Largest Contentful Paint、読み込みパフォーマンスを測定します。
- FID: First Input Delay、インタラクションパフォーマンスを測定します。
- CLS: Cumulative Layout Shift、視覚的な安定性を測定します。
なぜCore Web Vitalsを評価指標として採用するのか
上記のCWVの説明からわかるように、コア指標はページの読み込み速度、ユーザー入力パフォーマンス、ページの視覚的安定性の3つの方向から、優れたページパフォーマンスが備えるべき特徴を評価しており、これらの3つの指標はユーザー体験の核心要素でもあります。以前の測定方法であるhero element time、つまり各ビジネスラインの開発者が独自の重要なページ要素を定義し、そのレンダリング完了時間でページのパフォーマンスを測定する方法と比較して、CWVの指標は明らかに包括的であり、より汎用的で、不正がしにくく、業界全体の検証を受けています。
以下は、Google公式による、CWV指標の最適化における実際のウェブサイトのパフォーマンス向上状況の統計です。
なぜページパフォーマンスが重要なのか?調査によると、Core Web Vitalsの改善はユーザーエンゲージメントとビジネス指標を向上させます。例えば:
- サイトがCore Web Vitalsの閾値を満たす場合、ユーザーがページ読み込みを放棄する可能性が24%低いことが研究で示されました。
- Largest Contentful Paint (LCP)が100ms短縮されるごとに、Farfetchのウェブコンバージョン率が1.3%増加しました。
- Cumulative Layout Shift (CLS)を0.2削減したことで、Yahoo! JAPANはセッションあたりのページビューが15%増加し、セッション継続時間が13%長くなり、直帰率が1.72パーセントポイント減少しました。
- NetzweltはCore Web Vitalsを改善し、広告収入が18%増加し、ページビューが27%増加しました。
- CLSを1.65から0に削減したことで、redBusのドメインランキングが世界的に大幅に向上しました。
LCP、FID、CLSのいずれも、その向上がビジネスの向上に確実に貢献することがわかります。これが、私たちがパフォーマンス最適化を行う理由であり、CWVを評価指標として選択する理由でもあります。
CWVを評価指標として選択するさらなる理由については、以下を参照してください。
したがって、私たちはパフォーマンスの評価指標をCore Web Vitalsとし、目標をGood Url基準を満たすこと、すなわち以下の通りとしました。
- LCP < 2500ms
- FID < 100ms
- CLS < 0.1
最適化手法
パフォーマンス最適化は古くから議論されているテーマであり、インターネット上には多くの既存のソリューションや手法が存在します。これらのソリューションや手法をそのまま適用しても、必ずしも目標を迅速に達成できるとは限りません。 例えば、有名なYahoo!のパフォーマンスルールには、「静的リソースは複数のドメインに分散させ、ブラウザの並行リクエスト数を増やすべき」とありますが、技術の発展とHTTP/2の普及により、このソリューションはもはや適用されません。また、ある記事では、「JavaScriptの配列反復メソッドforはforEachよりもはるかに高速なので、より良いパフォーマンスのためにforを使用すべき」と書かれています。しかし、数日かけてすべてのforEachをforに置き換えても、CWV指標には全く変化がないかもしれません。
したがって、パフォーマンス最適化を行うには、他者のソリューションを単に模倣するのではなく、パフォーマンス最適化の手法を習得する必要があります。まさに「理論が実践を導く」という言葉の通りです。パフォーマンス最適化にとっての手法とは、測定、分析、検証です。
測定
ページの現状を測定できなければ、最適化は始まりません。
したがって、パフォーマンス最適化の最初の課題は、ページのパフォーマンス現状を測定するソリューションを持ち、その後の分析と最適化のためのデータサポートを提供することです。
前述の通り、私たちはCWVをパフォーマンス評価指標として選択しました。GoogleはPageSpeed Insights、Chrome開発者ツール、Search Console、web.dev測定ツールなど、多くのCWV検出方法を提供しています。
しかし、これらには共通の問題があります。それは、オンラインの実際のユーザーの全体的な統計値をリアルタイムで検出できないことです。PSI(PageSpeed Insights)のようなテストを通じてローカルで単一の評価結果を見るか、Google Search Consoleのように一定期間遅れてから大量のユーザーの実際の統計値を見るしかありません。
リアルタイムのパフォーマンスデータは私たちにとって非常に重要です。リアルタイムデータがなければ、以下の問題が発生します。
- 実験的なソリューションを迅速に検証できない。ソリューションを導入するたびに2週間待ってから効果を確認するのでは、効率が悪すぎます。
- 大規模な改修の場合、パフォーマンスが著しく低下してもリアルタイムのフィードバックがなければ、2週間後にデータを確認した時にはすでにビジネスに大きな損失を与えている可能性があります。
したがって、私たちは最適化戦略や最適化方向が正しいかどうかを指導するために、パフォーマンスデータをリアルタイムで監視するソリューションを持つ必要があります。
最終的に、私たちはweb-vitalsを使用してCWVの値を取得し、ICBUの統一パフォーマンス監視スクリプトbig-brotherに適切なデータポイントを追加して、各ユーザーのパフォーマンスデータをレポートし、対応するパフォーマンス監視とレポートを構築してページのパフォーマンスデータをリアルタイムで監視しました。詳細については、Google Core Web-Vitals 統計&監視を参照してください。
PS:現在、より詳細なパフォーマンスデータを迅速に取得するために、直接agadoに接続できます。
分析
前のステップで取得したパフォーマンスデータと組み合わせて、現在の各ページのパフォーマンス現状を体系的に分析できます。それが本当に遅いのか、なぜ遅いのか、具体的にどこが遅いのかを知ることで、的を絞った最適化を行うことができます。
典型的なフロントエンドとバックエンドが分離されたページを例にとると、LCPの構成要素は以下の通りです。
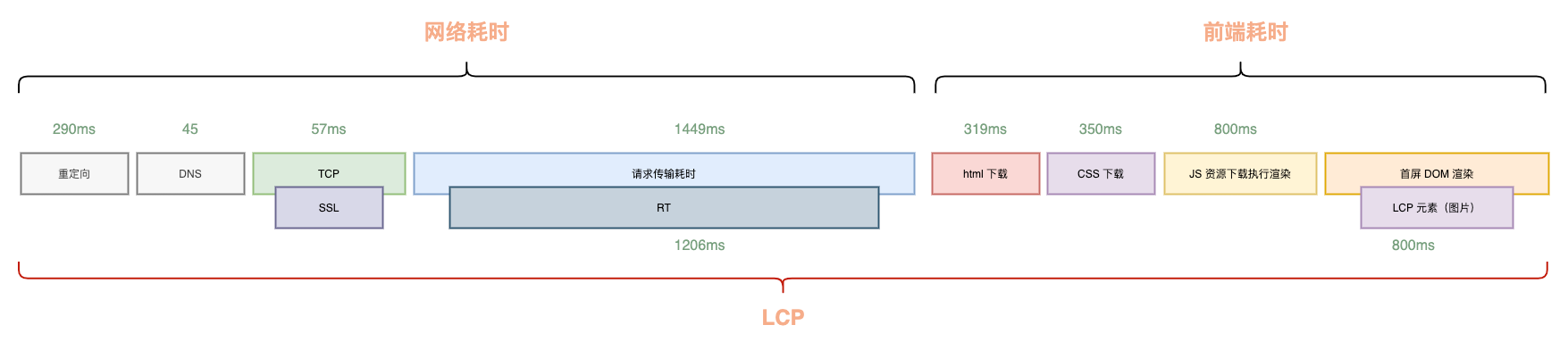
ユーザーがブラウザを開いてからページのLCPが表示されるまでには、接続確立、バックエンド応答、HTML転送ダウンロード、フロントエンドリソースダウンロード、そして最終的な解析レンダリングという非常に長い経路を経るため、最終的なLCPは2500msから大きくかけ離れていることが多いです。
LCPの時間を短縮する方法は、技術的な詳細を考慮しない場合、各所要時間を短縮するか、可能な限り並行処理することだと容易に考えられます。これがLCP最適化の核心的な原則です。「削減できるものは削減し、削減できないものは並行処理する」です。
LCPの構成から見ると、リダイレクト、DNS解決、接続確立、ネットワーク転送時間は主にサードパーティまたはユーザー自身のネットワーク状況に制限されるため、私たちにできることは多くありません。
したがって、核心的な最適化の方向は、私たちが制御できるネットワーク所要時間以外の場所に焦点を当てるべきです。すなわち:
- LCPのタイムライン構成の最適化:現在のLCPタイムラインの中で、削除できるもの、並行処理できるもの。
- LCPのタイムライン構成の各ステップ自体の所要時間最適化:ネットワーク所要時間以外に、バックエンドのRTおよびフロントエンドリソースのダウンロード、解析、実行時間の最適化。
これら2つの方向の最適化は、それぞれレンダリングアーキテクチャの最適化とクリティカルレンダリングパスの最適化を通じて分析・最適化を行います。バックエンドRTの最適化については、この記事では扱いません。
レンダリングアーキテクチャの最適化
マクロな視点から見ると、レンダリングアーキテクチャの選択は非常に重要です。合理的なアーキテクチャ選択は、システムのパフォーマンスの下限を向上させ、その後のさらなる最適化の基盤を築きます。
LCP最適化の核心的な原則「削減できるものは削減し、削減できないものは並行処理する」に従うと、前述のLCP構成図から以下の点が容易にわかります。
- 従来のページレンダリングはJSの読み込みに依存しないため、この時間は削減できる可能性があります。
- フロントエンドリソースの読み込みとバックエンド応答という2つの大きな所要時間構成要素は直列関係にありますが、これらを並行処理できないでしょうか。
これら2つの最適化方向は、レンダリングアーキテクチャの最適化ソリューションである同型変換とストリーミングレンダリングに対応します。
同型変換
レンダリングアーキテクチャにおいて最も費用対効果の高い最適化は同型変換です。インフラのサポートがあれば、比較的少ない人的資源の投入で、確実で大きなパフォーマンス向上を得ることができます。一般的に、同型変換は500〜800msのパフォーマンス向上をもたらします。
前述の通り、現在、当社のビジネスの大部分はフロントエンドとバックエンドが分離されたアーキテクチャを採用しています。このアーキテクチャの利点は、フロントエンドとバックエンドのコミュニケーションおよびリリース・保守コストを削減し、両者が並行して開発し、独立してコードベースを保守できるため、安定性も高まります。しかし、このアーキテクチャの問題は、フロントエンドとバックエンドが分離されているため、バックエンドが出力するHTMLには骨格しかなく、コンテンツがないことです。フロントエンドで再度レンダリングを行う必要があり、このフロントエンドレンダリングはJSのダウンロードと初回表示データの取得に依存するため、レンダリング経路が長くなります。
この余分なレンダリング時間を削減できないでしょうか?答えは「できます」です。同型直出しは、この問題を解決するためにあります。同様にフロントエンドとバックエンドが分離されたアーキテクチャでも、開発効率や協力効率を損なうことなく、フロントエンドとバックエンドの両方で実行できる単一のJSコードを通じてページの直出しを実現できます。
これにより、フロントエンドの余分なJSダウンロード、解析、実行、レンダリングの時間を省くことができ、削減される時間は通常500〜800msですが、その代償として同型サービスを別途保守する必要があります。
同型サービスとしては、現在、汎用同型サービスsilkworm-engine(社内構築サービス)、店舗が独自に構築した同型サービス、およびマーケティングガイドがグループの天馬プラットフォームに接続することで提供される同型サービスがあります。一般的なビジネスの場合、silkworm-engineに接続するだけでよく、接続自体のコストも高くありません。
ストリーミングレンダリング
2010年には、Facebookのエンジニアがbigpipeというページレンダリングソリューションを提案しました。これは、大きなページを複数のpageletに分割し、段階的にページレンダリングを完了させることで、一度に大きなページをレンダリングするバックエンドの所要時間が長すぎる問題を解決することを目的としていました。
このソリューションのアイデアは非常に先進的でしたが、侵襲性が大きいという欠点があり、既存の技術アーキテクチャではこのような改修は不可能に近いでしょう。しかし、その背後にある原理、すなわちHTTP/1.1(当時、現在はHTTP/2以降でデフォルトでサポート)のチャンク転送エンコーディングの特性は、より低コストな最適化、つまりストリーミングレンダリングを私たちに導いてくれます。これは、バックエンドの一括ビジネス処理VMテンプレートレンダリングと返却を2つのステップに分割します。
- まず、ビジネスロジックに依存しないHTMLの
<head>部分を返却し、ブラウザはそれを受け取って静的リソースのダウンロードを開始できます。 - 最初の部分を返却した後、ビジネスロジック処理(商品データのリクエスト計算など)を同期的に行い、VMをレンダリングしてHTMLの残りの
<body>部分を返却します。
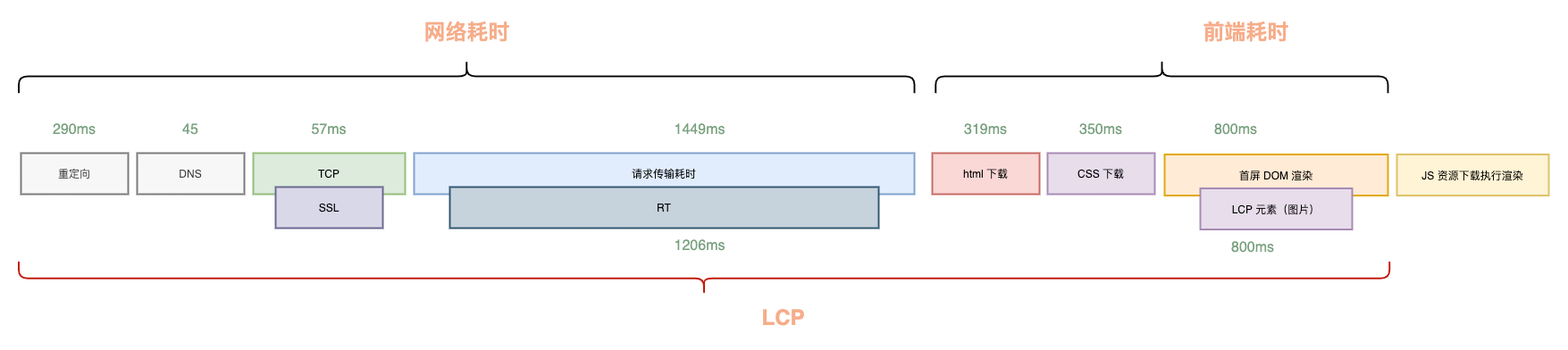
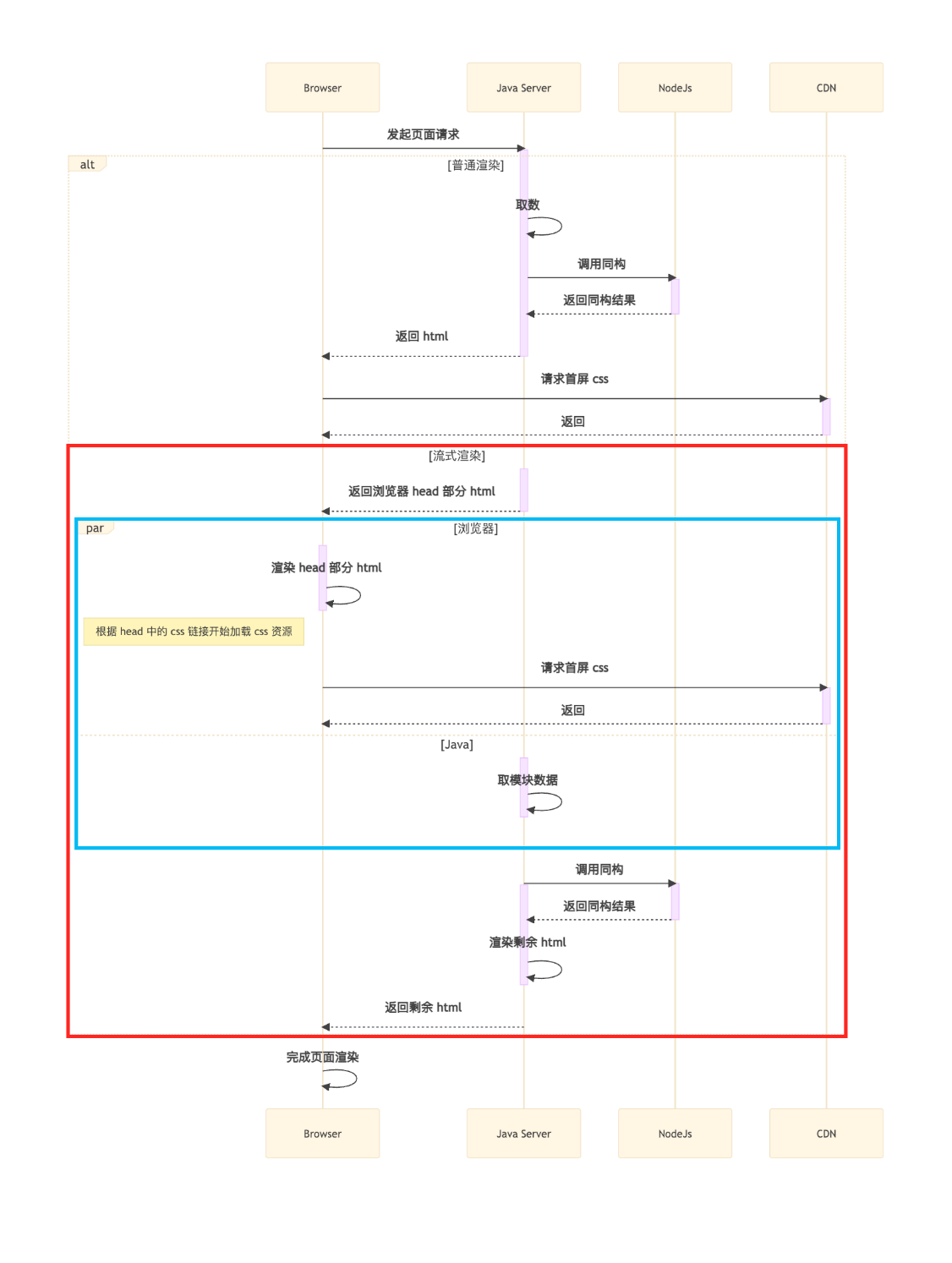 ストリーミングレンダリングのソリューションでは、青い枠内の
ストリーミングレンダリングのソリューションでは、青い枠内の<head>のダウンロード解析、および初回表示CSSなどのリソースのダウンロードが、バックエンドのデータ取得計算と並行して行われていることがわかります。
これにより、Min(フロントエンドの初回表示リソースダウンロード時間、バックエンドRT)の時間を節約でき、通常300〜500ms程度の最適化が可能です。最適化後のタイムラインは以下の通りです。 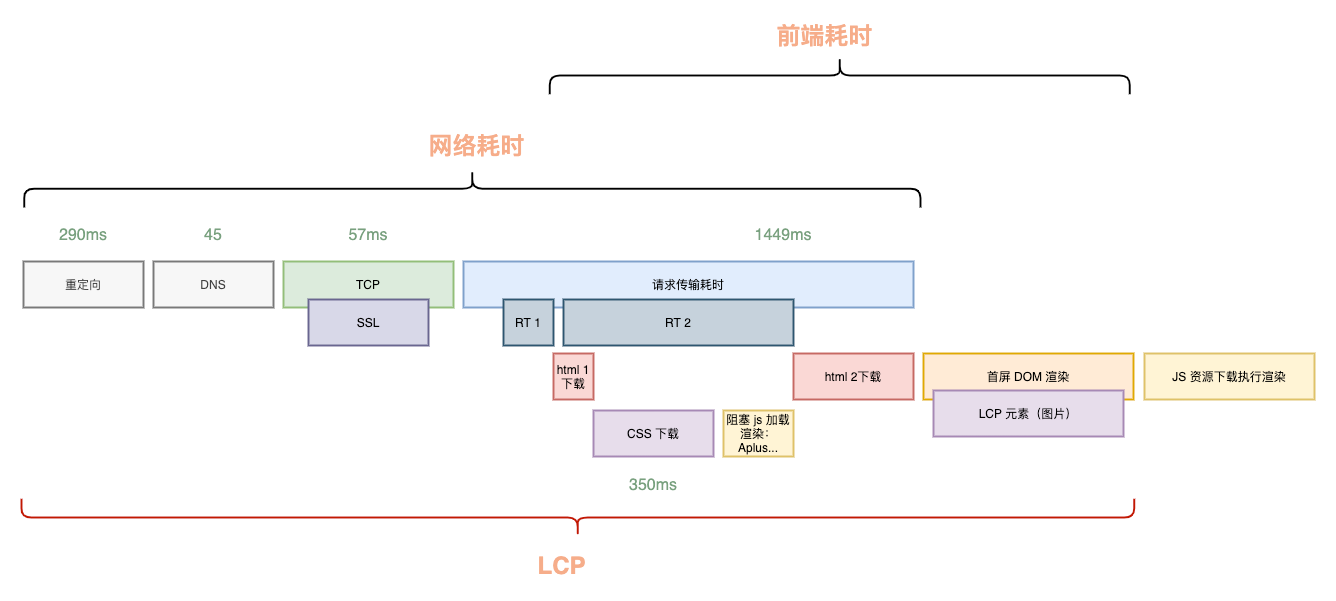 ストリーミングレンダリングの接続には、すでにエンジニアリングソリューションがあります。
ストリーミングレンダリングの接続には、すでにエンジニアリングソリューションがあります。
- Javaアプリケーションは、ストリーミングレンダリング - Java側接続ドキュメントを参照して接続できます。
- Node.jsのEggアプリケーションは、Spark:5分でストリーミングレンダリングに接続を参照できます。
レンダリングアーキテクチャのまとめ
同型変換とストリーミングレンダリングという2つのレンダリングアーキテクチャの最適化を通じて、通常1秒以上の改善が見込めます。また、ビジネスシナリオを選ばず、手順通りに行えば、ほとんどすべてのページでこれら2つの改修を行い、目に見える効果を得ることができます。
同時に、他のレンダリングアーキテクチャの最適化を行わない限り、通常、この1秒以上の改善は、ページが属するプロジェクトの機能イテレーションによって劣化することはなく、パフォーマンスの下限が保証されます。
クリティカルレンダリングパスの最適化
MDNにおけるクリティカルレンダリングパス(Critical rendering path、以下CRP)の定義を引用します。
The Critical Rendering Path is the sequence of steps the browser goes through to convert the HTML, CSS, and JavaScript into pixels on the screen. Optimizing the critical render path improves render performance. The critical rendering path includes the Document Object Model (DOM), CSS Object Model (CSSOM), render tree and layout.
簡単に言えば、ブラウザがHTML、CSS、JavaScriptを画面上のピクセルに変換するために経る一連のステップであり、ドキュメントオブジェクトモデル(DOM)、CSSオブジェクトモデル(CSSOM)、レンダリングツリー、レイアウトを含むこれらのステップを最適化することで、初回表示レンダリングパフォーマンスが向上します。
CRPの最適化は、ブラウザのレンダリング原理に関わります。
- ブラウザはまずDOMをダウンロードして解析し、DOMツリーを生成する必要があります。
- DOMの解析中にCSSファイルに遭遇すると、それをダウンロードして解析し、CSSOMを生成します。
- DOMツリーとCSSOMに基づいてレンダリングツリーを生成します。
- レンダリングツリーに基づいてレイアウトを行います。
- レイアウト完了後、具体的なコンテンツを画面に描画します。
DOMまたはCSSOMが変更された場合、例えばJavaScriptでDOMノードを操作したり、動的にスタイルタグを挿入したりすると、ブラウザは上記のステップを再実行します。CRPの原理を理解すると、CRPに影響を与えるいくつかの要因が見えてきます。
- HTMLファイルのダウンロードと解析時間
- CSSファイルのダウンロードと解析時間
- 同期JavaScriptファイルのダウンロードと解析
- DOMとCSSOMのサイズ
- およびレイアウトと描画の時間
このうち、HTML、CSS、および同期JavaScriptリソースは、CRPの各段階に影響を与えるため、クリティカルリソースと呼ばれます。したがって、クリティカルリソースのダウンロード解析とDOMおよびCSSOMのサイズを最適化するだけでよいのです。
- クリティカルリソースの最適化については、クリティカルリソースの数を減らし、リソースのサイズを小さくし、クリティカルリソースの読み込み順序とキャッシュを調整することで最適化できます。
- DOMとCSSOMの最適化については、DOMノードの数を減らし、CSSOMのサイズを小さくし、DOMとCSSOMの階層を減らすことで最適化できます。
キャッシュ
静的リソースのキャッシュを利用することで、リソースのダウンロード時間を短縮し、クリティカルパスの長さを短縮し、ページのレンダリング速度を向上させることができます。 具体的なソリューション:
- リソースキャッシュ期間の設定
- 静的リソースのCDN経由配信
- 動的・静的リソースの分離
静的リソースのキャッシュ設定
HTTPキャッシュの具体的な仕様定義については、この記事では詳しく述べません。簡単に言えば、キャッシュは2つのカテゴリに分けられます。
- 強力なキャッシュ:キャッシュ有効期間内はリクエストを発行せず、直接ローカルキャッシュの内容を使用します。
- 弱いキャッシュまたは交渉キャッシュ:ローカルキャッシュの有効期限が切れた後、リクエストを発行してサーバーと交渉し、その後ローカルキャッシュを使用します。
一般的なAssetsアプリケーションの場合、プロジェクトのルートディレクトリに.assetsmetafileファイルを追加することで、リソースのキャッシュ期間を自分で指定できます。以下の例は、ブラウザとCDN(特定のベンダー)の両方に1年間キャッシュさせる設定です。
cache-control:max-age=31536000,s-maxage=31536000これにより、リソースが属するアプリケーションがリリースされていない限り(非上書きリリースリソースのみ、リンクが変更されていない場合)、1年間のリクエストは直接キャッシュされた内容を使用します。
CDNの利用
ご存知の通り、CDNは強力なネットワークとサーバーを通じて、静的リソースをユーザーに最も近いノードにキャッシュすることで、リソースのダウンロード時間を短縮します。
CDN静的アクセラレーション
静的リソースをCDNに配置するのは一般的な操作ですが、この記事で改めて取り上げるのは、当社のウェブサイトにはまだ<img src="//icbu-cpv-image.oss-us-west-1.aliyuncs.com/Had9f38eda3d942aa9e65ee919b0660fU.jpg_300x300.jpg">のようなCDN配信されていないリソースがあり、ユーザーが毎回オリジンサーバーからリソースをリクエストしてダウンロードする必要があるためです。
CDN動的アクセラレーション
CDN動的アクセラレーションという概念はあまり一般的ではないかもしれません。その「動的」とは、静的アクセラレーションにおける「静的」との対比であり、作用する対象が異なります。
原理を簡単に言えば、CDNの本来の利点、つまりユーザーに近いエッジノードを持ち、広範囲に分散していることを利用します。CDNベンダーの専門的な最適化を通じて、CDNノードマシンからユーザーからオリジンサーバーへのより最適な経路を見つけ出し、外部ネットワークの多層ゲートウェイを回避します。これにより、CDNノードとオリジンサーバー間のネットワーク所要時間を短縮し、ユーザーの動的リクエストがCDNノードを経由してオリジンサーバーにアクセスすることで、ユーザーが直接オリジンサーバーにアクセスするよりもはるかに高速になります。
当社の統計によると、動的アクセラレーションの収益は200ms以上です。
キャッシュヒット率の向上
リリース頻度が高すぎると、バージョン番号の変更によりリソースに対応するURLが頻繁に変化し、ローカルキャッシュはローカルストレージリソースを占有するだけで、本来の役割を失ってしまいます。
そのため、ページの静的リソースのキャッシュヒット率を向上させる必要があります。一般的にキャッシュヒット率を向上させる方法は、動的・静的リソースの分離です。
ページが依存するJavaScript、CSSを階層化することで、React、ReactDOM、Fusionなどの共通の依存関係を1つの共通バンドル(静的リソースと呼びます)にまとめ、ビジネス関連の依存関係をビジネス関連のバンドル(動的リソースと呼びます)にまとめることができます。
静的リソースのリリース頻度は動的リソースのリリース頻度よりもはるかに低いため、ほとんどの機能イテレーションでは、上位のビジネスアプリケーションのみがリリースされます。ユーザーにとっては動的リソースのみをダウンロードすればよく、静的リソースは変更がないため、キャッシュから直接読み込むことができ、リソースの読み込み速度が向上します。
これにより、ページ全体を1つのJavaScriptまたはCSSバンドルにまとめることで、たとえ1行のコードがリリースされただけでも、ユーザーがJavaScript、CSSバンドル全体を再ダウンロードする必要があるという問題を回避し、全体的なリソースキャッシュヒット率を向上させることができます。
接続確立
前述の有名なYahoo!のパフォーマンスルールには、「静的リソースは複数のドメインに分散させ、ブラウザの並行リクエスト数を増やすべき」とありました。これは、ブラウザが同じドメインからのリクエスト数を制限し、当時のHTTP/1.xでは1つのTCP接続で1つのHTTPリクエストしか処理できなかったため、ブラウザが同時に複数のリソースを並行してリクエストできるようにするために提案された最適化ソリューションでした。
HTTP/2の時代になると、1つのTCP接続で複数のリクエストを並行して行うことができるようになり、HTTP/1.1のConnection: Keep-Aliveと組み合わせて接続を再利用することで、以前の最適化ソリューションはあまり意味がなくなりました。
ドメインの集約
それどころか、リソースを異なるドメインに分散させたことで、各ドメインでDNS解決や接続確立などのプロセスを再度行う必要が生じ、以前の最適化手法が負の最適化になってしまいました。
そのため、複数の異なるドメインに分散しているアドレスを1つのドメインに集約し、DNS解決の回数を減らし、接続の再利用と並行リクエストによってより良い効果を得る必要があります。
HTTP/2のさらなる特性については、HTTP/2 – A protocol for greater performanceを参照してください。
事前接続確立
前述の通り、DNS解決と接続確立は非常に時間のかかる操作です。そのため、ブラウザはDNS解決と接続確立を事前に行う方法を提供しており、それぞれdns-prefetchとpreconnectです。
dns-prefetchはHTML5で追加された新しい属性で、ブラウザに特定のドメインを事前に解決するように指示します。これにより、ブラウザがそのドメインを解決する必要があるときに、再度解決する必要がなくなり、キャッシュされた結果を直接使用できます。DNS-Prefetchは2つの方法で使用できます。
<link rel="dns-prefetch" href="https://s.alicdn.com/" />preconnect:ブラウザにTCP接続、DNS解決、TLSハンドシェイクなどの操作を事前に確立するように指示します。これにより、ブラウザがそのドメインを使用する必要があるときに、これらの操作を再度行う必要がなくなり、キャッシュされた結果を直接使用できます。headタグに以下のmetaタグを追加するだけで済みます。
<link rel="preconnect" href="https://s.alicdn.com" />PS: 注意点として、preconnectは実際に接続を確立するため、比較的重い操作です。したがって、クリティカルリソースに対応するドメインでのみ使用し、過剰な事前接続はページに負の影響を与える可能性があるため避けてください。 dns-prefetchはpreconnectよりもブラウザの互換性が優れているため、dns-prefetchとpreconnectを組み合わせて使用することをお勧めします。
<link rel="preconnect" href="https://s.alicdn.com/" crossorigin />
<link rel="dns-prefetch" href="https://s.alicdn.com/" />プリロード
ページが依存するコアリソースについては、リソースのプリロードを利用してクリティカルリソースを事前にダウンロードすることで、CRPにかかる時間を短縮できます。効果は以下の通りです。
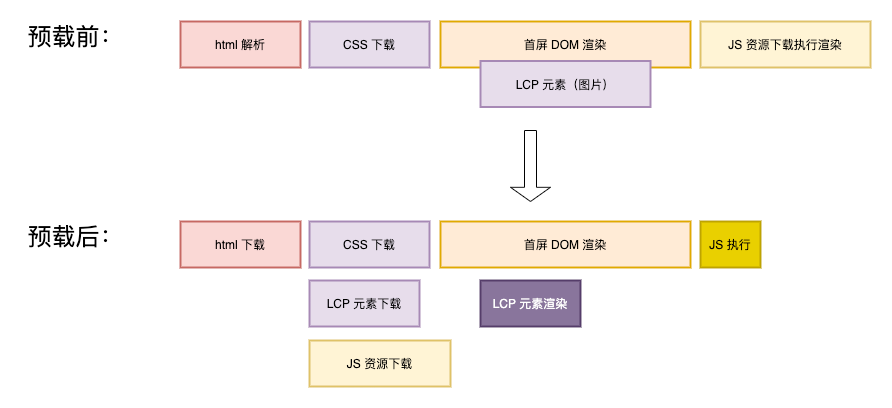
HTMLの<head>にpreloadのmetaタグを追加することで実現します。
- CSS:
<link rel="preload" href="styles/main.css" as="style"/> - JS:
<link rel="preload" href="main.js" as="script" />
その後、対応するプリロード済みのリソースを読み込む必要がある場合、ネットワークから再度取得する必要がなくなります。
非コアコンテンツの非同期読み込み
当社のウェブサイトは非常に豊富なコンテンツを持っており、これは機能が複雑でコードの量が多いことを意味します。もし初回表示全体が読み込まれるまで使用できないとすると、ユーザー体験は非常に悪くなります。
この問題を解決するために、非コアコンテンツを非同期で読み込むことができます。これにより、ユーザーは初回表示が完了した後すぐにウェブサイトのコア機能を使用でき、非コアコンテンツはその後読み込みが完了した後に使用できます。
ソリューションとしては、webpackでコードを構築しているユーザーは、dynamic importを直接使用して実現できます。
例えば、PPCのPCページでは、ユーザーがよりコアな商品リストを早く見られるように、左側のフィルタリングを非同期で読み込みました。
import React, { lazy } from "react";
import SSRCompatibleSuspense from "../../component/ssr-suspense";
import { Icon } from "@alifd/next";
function LeftFilterAsync({ data }: { data: PPCSearchResult.PageData }) {
const TrafficLeftFilter = lazy(() =>
// NOTE:页面的左侧筛选,功能复杂,但不属于用户首屏需要的内容,所以异步加载
import(/* webpackChunkName: "left-filter" */ "@alife/traffic-left-filter")
);
const handleChange = (link: string) => {
xxx;
};
return (
<SSRCompatibleSuspense fallback={<Icon type="loading" />}>
<TrafficLeftFilter
data={data?.snData}
i18n={data?.i18nText}
handleChange={handleChange}
/>
</SSRCompatibleSuspense>
);
}
export default LeftFilterAsync;選択的レンダリング
コードをさらに分割できないが、レンダリングするコンテンツが非常に多く、DOMノード数が膨大で、CRPの時間が長くなる場合、初回表示ではより重要なコンテンツの一部を選択的にレンダリングすることができます。これにより、初回表示のレンダリング時間を短縮できます。
例えば、ショールームのモバイルページでは、初回表示でバックエンドから48個の商品が返されますが、モバイルデバイスのほとんどは初回表示で4個の商品しか表示できません。そのため、初回表示では最初の8個の商品のみをレンダリングし、残りの商品はJavaScriptの準備ができた後に二次レンダリングを行います。
これにより、同期直出しのページでは、HTMLのサイズが削減され、HTMLのダウンロード速度が向上するとともに、初回表示のDOMノード数が削減され、ブラウザがDOMツリーを生成する時間が短縮されます。
最終的にCRPにかかる時間が短縮されます。
FIDおよびCLSの最適化
これまでの長い記述はLCP関連の最適化についてでしたが、バイヤー向けのページは主に純粋な表示型ページであり、通常は非常に複雑なインタラクションがないため、FIDとCLSの問題はあまり顕著ではありません。開発者が意識するだけで十分です。
FID
FID: First Input Delay、ユーザーがウェブサイトと初めてインタラクションを開始してから、ブラウザが実際にそのインタラクションに応答できるようになるまでの時間。
この時間は主にJavaScriptの実行時間によって決まります。ブラウザのメインスレッドがJavaScriptを実行している間は、ユーザーの操作に応答できないため、最終的にFIDに影響します。したがって、最適化の方向性は以下の通りです。
- JavaScriptの実行時間の短縮
- JavaScript内の重い計算タスクの分割
JS実行時間の短縮
ページが依存するJavaScriptの総容量を制限することで、実行時間を非常に直感的に短縮できます。
ページのメインJavaScriptについては、コード分割を利用して、初回表示のコア機能ではないコードの読み込みを遅延させ、コードが実際に使用されるとき、またはアイドル時にのみ読み込むことで、メインスレッドを空け、JavaScriptの実行時間を短縮します。
ページが依存するセカンダリパッケージについては、厳密に審査し、React、Fusionなどの同じパッケージや依存関係が重複して導入されるのを避ける必要があります。これにより、JavaScriptのサイズが増大し、実行時間が増加します。例えば、あるシナリオで導入されたセカンダリSDKは、当社のホストページコードの300KBよりもはるかに大きい1.6MBものサイズがあり、ここには大きな最適化の余地があります。
サードパーティスクリプトの導入を制御するか、可能な限り読み込みを遅延させます。一部の広告ページには多くのサードパーティの統計スクリプトが依存しており、これらのスクリプトの読み込みはページのレンダリングをブロックし、FIDに影響を与えます。
JSの重い計算タスクの分割
重い計算タスクについては、requestAnimationFrameを利用して、計算タスクを複数のフレームに分割して実行することで、JavaScriptの実行時間を短縮し、ブラウザにユーザーの操作に応答するためのより多くのアイドル時間を与えることができます。
分割できない計算タスクの場合は、web workerを利用して、計算タスクをワーカー内で実行することで、メインスレッドをブロックしないようにすることができます。
CLS
CLS: Cumulative Layout Shift、ユーザー入力から500ミリ秒以内に発生しなかったレイアウトシフトのシフトスコアの合計を計算することで、コンテンツの不安定性を測定します。
CLSが悪化する主な原因:
- サイズ指定のない画像
- サイズ指定のない広告、埋め込みコンテンツ、iframe
- 動的に挿入されるコンテンツ
- 不可視テキストのちらつき(FOIT)/スタイルなしテキストのちらつき(FOUT)を引き起こすウェブフォント
- DOMを更新する前にネットワーク応答を待つ操作
国際サイトのシナリオでは、特に以下の点に注意が必要です。
- 画像には
autoではなく具体的な幅と高さを設定する必要があります。これにより、ブラウザは画像がダウンロードされる前にどれだけのスペースを確保すべきかを知ることができます。 - ページ本体部分は可能な限り同期的に直出しし、非同期レンダリングされるブロックについては、プレースホルダーを適切に設定し、非同期レンダリングによってページが飛び跳ねるのを防ぎます。
基本的にこれらを実践すれば、CLSは基準を満たすことができます。
戦略の蓄積
この1年間の最適化プロセスで、私たちはパフォーマンス最適化を迅速に進めるためのいくつかのツールと経験を蓄積しました。
ツールおよびシステムの蓄積
- agado*:*エンドアーキテクチャチームが構築したグローバルパフォーマンス測定プラットフォーム。数行のコードで包括的なパフォーマンス測定システムに効率的に接続できます。
- silkworm engine:バイヤー向け基盤技術が約5年前に構築を開始した汎用同型レンダリングサービス。特定のソリューション(店舗、天馬など)以外のページで同型機能を迅速に導入するニーズを満たし、現在は@咸鱼が保守しています。
- ストリーミングレンダリングセカンダリライブラリ:ストリーミングレンダリングに迅速に接続するためのソリューションで、初期段階で各層のプロキシを統合し、バックエンドの接続コストを3人日から時間単位に削減できます。
達成された成果
SEOパフォーマンス最適化
Google Search ConsoleバックエンドのGoodUrl比率の増加:
- PC:0 -> 85.9%
- モバイル:0 -> 95.1%
具体的なパフォーマンス指標(矢印は最適化後の結果を示します):複数のシナリオでページのパフォーマンスが大幅に向上し、CLSとFIDはすべてCWV Good Url基準を達成しました。特に最適化した2つのシナリオでは、LCPもGood Url基準を達成しました。 SEOシナリオでは、パフォーマンス向上による検索エンジンでの加重と到達率の向上により、複数のシナリオで**10%〜20%**のUV増加が見られ、ユーザー規模が大幅に拡大しました。
有料ページ最適化
- Wap DPAページ:LCPが約500ms短縮され、ビジネス指標:UVが約9%向上し、クリック率、クロスデバイスなどの他のビジネス指標も大幅に向上しました。
- PC PLAページ:LCPが約900ms短縮され、ビジネス指標:コアクリックが16.1%上昇、UVが4.6%増加しました。
- その他、多くの実験中のプロジェクトでも、ビジネスデータが様々な程度で増加していることが確認されています。
実際の事例
これまでに多くの理論的な知識を述べてきましたが、次に実際の例、すなわちモバイルショールーム(SEOランディングページ)の最適化を通じて、上記のメソッドに基づいてLCP、FID、CLSのすべてが基準を満たしていなかったページをGood Urlに最適化する方法を検証します。
現状分析
ショールームを引き継いだ当初、パフォーマンスが非常に悪いことだけは知っていました。Google Search Consoleのバックエンドで、当社のウェブサイトのGood Url達成率が0%であることがビジネス側から報告されていたためです。つまり、LCP、CLS、FIDのすべてが不合格でした。しかし、具体的にどの程度悪いのか、どこが悪いのかは全くわかりませんでした。
最適化の要望は非常に切迫していましたが、現状がどのようなものかさえわからなければ、当然最適化はできません。そこで、まず現状を測定するソリューションが必要でした。分析と調査の結果、Googleのweb-vitalsライブラリを使用してユーザーデータを取得し、ICBUが以前から接続していたbig-brotherを使用して収集したデータをレポートし、同時にxflushを設定してデータの変動傾向をリアルタイムで表示することにしました。
これが最終的なパフォーマンス集計ダッシュボード監視です。 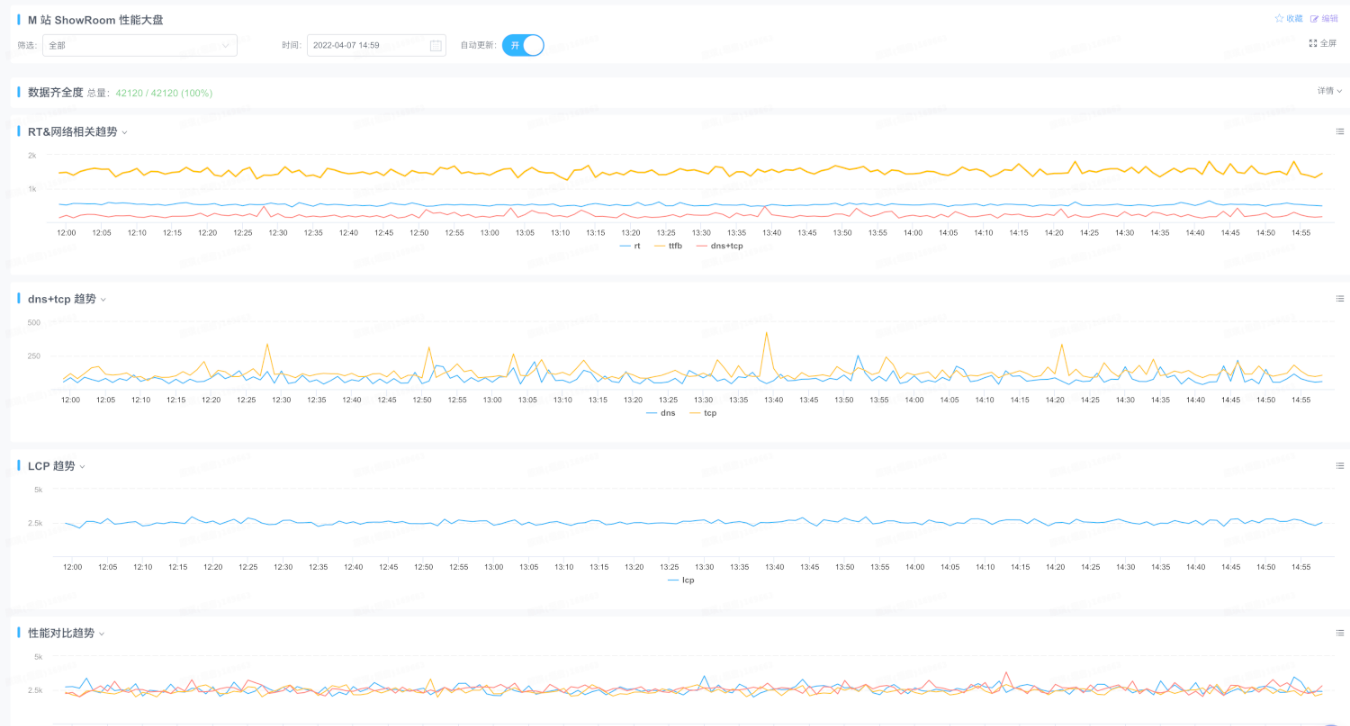
測定ソリューションができた後、パフォーマンスの現状を把握しました。データはかなり悪く、LCP、CLS、FIDのすべてを最適化する必要がありました。
パフォーマンスデータが得られた後、ショールームの技術アーキテクチャを見てみましょう。
- UIフレームワークはrax + dxを採用
- raxは当時のグループのReactライクなUIライブラリ
- dxはクロスプラットフォーム開発問題を解決できるソリューションで、主にAndroidとiOSのアプリ内動的設定に使用され、Web版にも互換性のある表示ソリューションがあります。
- レンダリング経路:ページ骨格はCDNに配置され、JavaScriptが非同期インターフェースを呼び出して初回表示データを取得し、非同期でページレンダリングを完了します。
- dxを使用しているため、バックエンドデータからdxテンプレートの文字列を取得し、フロントエンドがその文字列を
evalしてdx-h5ライブラリを通じてraxコンポーネントに変換し、raxがページにレンダリングします。
- dxを使用しているため、バックエンドデータからdxテンプレートの文字列を取得し、フロントエンドがその文字列を
- スタイルファイル:raxとdxを使用しているため、最終的にはすべてインラインスタイルでスタイルレイアウトが実現されており、ブラウザがキャッシュできる独立したCSSファイルはありません。
初回同型変換
まずLCPの構成を見てみましょう。  ページの非同期レンダリングにより、HTMLがCDNに配置されても大きな助けにはならず、レンダリング経路全体が非常に長くなっていました。私たちは引き継いだ後、まず同型変換を行いました。
ページの非同期レンダリングにより、HTMLがCDNに配置されても大きな助けにはならず、レンダリング経路全体が非常に長くなっていました。私たちは引き継いだ後、まず同型変換を行いました。
元々ページはrax + dxで、raxは空のシェルで、主なコンテンツはdxを通じてレンダリングされていたため、dxの同型変換に接続する必要がありました。ちょうど隣のチームにdxの同型サービスがあったので、試してみました。
まず、Akamaiの担当者と話し合い、ショールームのHTML静的化ソリューションをCDNから削除し、フロントエンドでいくつかの改修を行い、DXの同型に接続しました。
接続完了後、dxの同型でも直出しは実現できましたが、非常に深刻な問題がありました。サーバーサイドデータのHTML構造とフロントエンドでレンダリングされる構造が異なっていたのです。
これにより、フロントエンドJavaScriptの二次レンダリングでページがちらつき、HTML構造が異なるためReactのようなhydrateができず、LCPの時間も二次レンダリング完了後の時間になってしまいました。同時に、ページのFID、CLSもあまり最適化されませんでした。
二回目の同型変換
dxの利点は、1つの設定で3つのプラットフォームで使用できることでした。しかし、Webプラットフォームでの実際の操作使用状況では、アプリ内の設定をWebプラットフォームに適用すると様々な適応問題が発生し、最終的には1つのコンポーネント、アプリ内はdxテンプレート設定、アプリ外は別の設定という形に発展しました。つまり、アプリ内とアプリ外は依然としてそれぞれ独立してテンプレートを保守しており、その利点は失われていました。
同時に、dxの使用により、多くの追加の問題が発生しました。
レンダリング効率の低さ:「ではグルダン、代償は何だ?」dxが解決しようとしたのはクロスプラットフォーム設定の問題でしたが、クロスプラットフォームには中間層が必要であり、層を追加するたびにコストがかかり、最終的に効率が低下し、LCPとFIDが高止まりしていました。以前保守していた担当者は、wasmのdxソリューションも試しましたが、それでも多くの問題を解決できませんでした。

dx同型側の出力構造とブラウザ側の構造が一致せず、さらなる最適化が不可能でした。
これらの問題の下で、私たちは最終的にショールームの再構築を選択し、元のdx、raxのソリューションを破棄し、Reactで書き直しました。
Reactでは様々な技術ソリューションが比較的成熟しており、再構築完了後、長年稼働しているsilkwormの同型サービスに接続しました。Reactの同型ソリューションは非常に成熟しており、dxのような二次レンダリングでページがちらつく問題は発生せず、接着層もないため、レンダリング効率もdxと比較して大幅に向上しました。

レンダリング経路が非常にシンプルになったことがわかります。監視データから見ると、LCPが約900ms短縮され、FIDは直接Good基準の100ms以下にまで低下しました。
クリティカルレンダリングパスの最適化
アプリケーションの分割
元のショールームアプリケーションを分割し、1つの大きなアプリケーションから2つのアプリケーションに分けました。基礎共通パッケージtraffic-baseと上位ビジネスアプリケーションtraffic-free-wapです。
通常のリリースはほとんどtraffic-free-wapのリリースであり、traffic-baseのリリース頻度は非常に低いため、キャッシュヒット率が向上し、リリースリスクも低減されました。
しかし、キャッシュの効果は長期的な影響であるため、短期的にはLCPの変化は見られませんでした。
aplusの非同期化
aplusはグループのデータポイントソリューションであり、様々なデータポイント、特にPVのレポートを実現するためにaplus.jsスクリプトに接続する必要があります。元のページのaplus.jsは同期的に読み込まれ実行されていたため、ページのレンダリングをブロックしていました。そこで、これを非同期読み込みに改造しました。
変更する必要があるのはバックエンドサービスのbeaconモジュールで、その中のscriptタグにasyncを追加するだけです。
[aplus]
aplusKeyUrl=.com
aplusKeyUrl=.net
aplusKeyUrl=.org
aplusKeyUrl=.cn
aplusKeyUrl=.hk
aplusKeyUrl=.vipserver
aplusLocation=header
aplusCmpType=find
aplusFilter=find"iframe_delete=true
aplusFilter=find"at_iframe=1
aplusFilter=find"/wangwang/update
aplusUrl=
<script
id="beacon-aplus"
async
src="//assets.alicdn.com/g/alilog/??aplus_plugin_icbufront/index.js,mlog/aplus_v2.js"
exparams="userid=\#getuid()\#&aplus&ali_beacon_id=\#getcookievalue(ali_beacon_id)\#&ali_apache_id=\#getcookievalue(ali_apache_id)\#&ali_apache_track=\#getcookievalue(ali_apache_track)\#&ali_apache_tracktmp=\#getcookievalue(ali_apache_tracktmp)\#&dmtrack_c={\#getHeaderValue(resin-trace)\#}&pageid=\#getpageid()\#&hn=\#gethostname()\#&asid=\#get_token()\#&treq=\#getHeaderValue(tsreq)\#&tres=\#getHeaderValue(tsres)\#">
</script>aplusの非同期化がリリースされた後、監視データからLCPが50ms改善されたことが確認されました。
事前接続確立、プリロード、およびドメイン集約
当社の最適化戦略に従い、ショールームページ全体の静的リソースドメインをs.alicdn.comに集約しました。
同時に、ドメインに対してDNSプリフェッチと事前接続確立を行いました。
<link rel="preconnect" href="https://s.alicdn.com" crossorigin />
<link rel="dns-prefetch" href="https://s.alicdn.com" />初回表示のいくつかの商品画像については、プリロードを行いました。
<link
rel="preload"
href="https://s.alicdn.com/@sc04/kf/H2df0c8cbb22d49a1b1a2ebdd29cedf05y.jpg_200x200.jpg"
as="image"
/>
<link
rel="preload"
href="https://s.alicdn.com/@sc04/kf/H423ae0f4cf494848bb5c874632270299J.jpg_200x200.jpg"
as="image"
/>
<link
rel="preload"
href="https://s.alicdn.com/@sc04/kf/Hdf15b5c8a7c544c2aee0b2616b2715e3K.jpg_200x200.jpg"
as="image"
/>リリース後、監視データからLCPが約200ms改善され、CWV Good Url LCPの境界に安定し、達成間近となりました。
ストリーミングレンダリングへの移行
上記の最適化を終えた後、ストリーミングレンダリングへの移行を開始し、フロントエンドとバックエンドが協力してストリーミングレンダリングのソリューションを完成させました。プレリリースでのテスト効果は非常に良好でした。しかし、リリース後もずっと有効にならず、原因を特定できませんでした。
最終的に、Akamaiの動的アクセラレーションを利用していることを思い出しました。これは、ユーザーのリクエストがまずAkamaiのCDNに到達し、その後当社のバックエンドサービスに到達することを意味します。当社のストリーミングレンダリングはバックエンドサービスで行われるため、CDN側で何らかの処理が行われ、有効にならなかった可能性があります。
CDNの担当者と話し合った結果、chunked response streamingの設定を追加する必要があることがわかりました。これを追加して再リリーステストを行ったところ、ストリーミングレンダリングがついに有効になり、リリース後LCPが直接500ms短縮され、CWV Good Url基準を達成しました。
CLSの最適化
LCPとCLSが基準を満たした後、残るはCLSがわずかに足りないだけでした。ショールームの場合、CLSの主な問題はヘッダーの高さが固定されていなかったことと、商品カード内のアイコンの位置が固定されていなかったことです。
- ヘッダーの問題については、ビジネス側と話し合い、ヘッダーの高さを確定し、プレースホルダーを追加しました。
- アイコン画像の問題については、固定幅を設定することで対応しました。
最適化のまとめ
ショールームの最適化プロセスは、私たちがフロントエンドで述べた最適化手法、すなわち測定→分析→実験に従って一歩ずつ進められ、最終的にCWV Good Url基準を達成し、Search Consoleのバックエンドで表示されるGood Rateは90%以上で安定しました。
同時に、Google Good Urlの要件を満たしたことで、Googleの検索ランキングの加重を獲得しました。Googleの担当者から提供された評価方法によると、モバイルショールームのクリック数は+10.6%、インプレッション数は+8.8%となり、約10%のUV増加をもたらしました。
まとめ
体系的な理論的指導がなければ、パフォーマンス最適化は非常に瑣末な作業になりがちです。Aを見つけてAを解決し、Bを見つけてBを解決する、といった具合で、ビジネスのイテレーションとともに徐々に劣化していくでしょう。また、方向性が間違っていると、多くの時間を浪費しても望む結果が得られない可能性が非常に高くなります。
この記事では、パフォーマンス最適化の理論から出発し、測定、分析、検証の3つの側面から、私たちがパフォーマンス最適化で行った実践について紹介しました。皆様のお役に立てれば幸いです。
現在、いくつかのパフォーマンスとビジネス上の成果を達成しましたが、有料ページなど多くのページにはまだ大きな最適化の余地があり、継続的な最適化と推進が必要です。