

This is a sharing document from within the company, with some sensitive information de-identified.
Project Overview
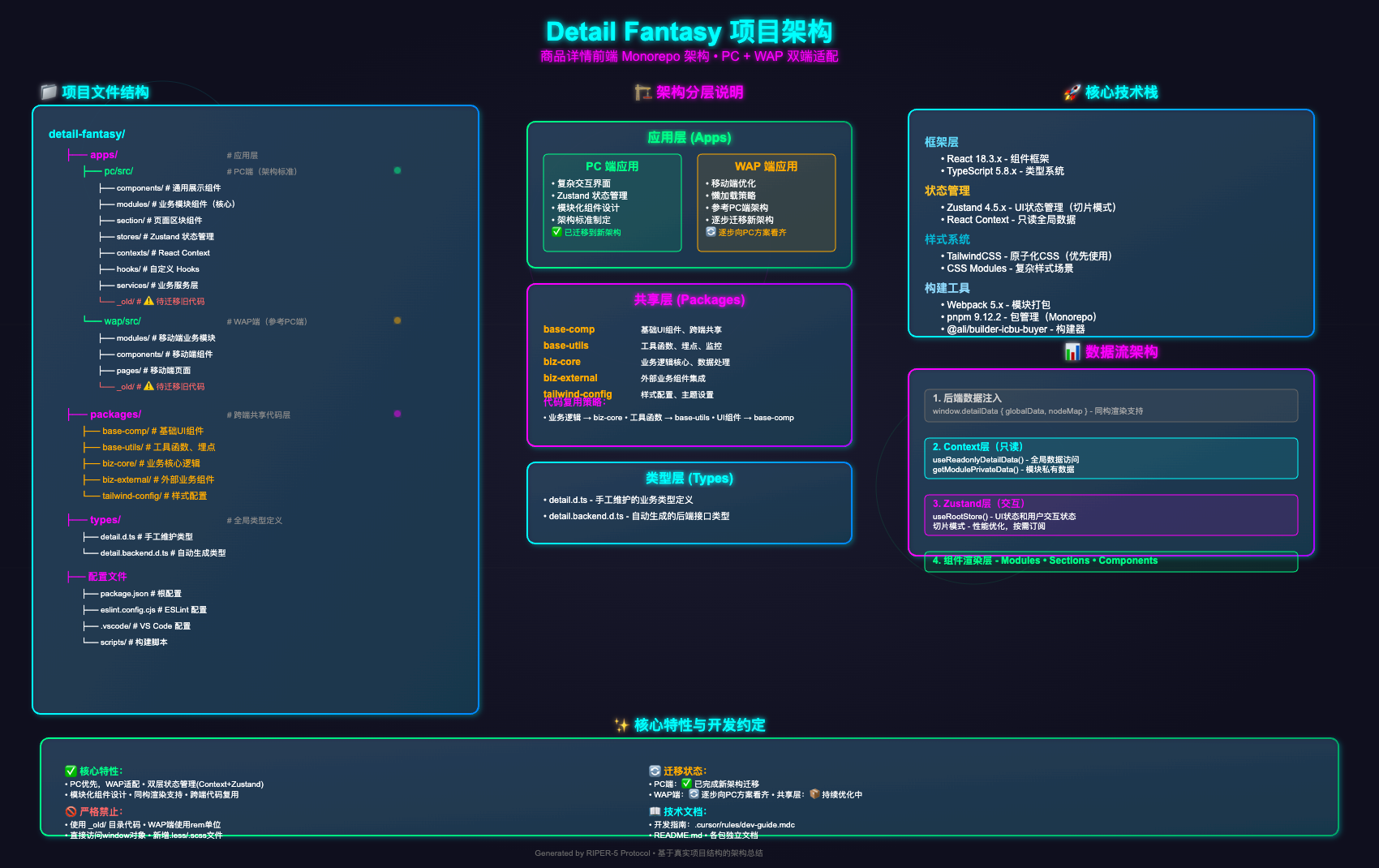
This is an SVG image drawn using Cursor, based on an understanding of the product detail page’s frontend application (because Cursor doesn’t support drawing).
Overall, it roughly describes the project’s situation, including its structure, technology stack, and the roles of some sub-packages. However, the image itself has many detailed issues, such as text overflow, overlap, and alignment problems. Despite multiple requests for AI to modify it, it couldn’t be fixed. This is the best AI could produce at a reasonable efficiency-to-cost ratio, so it’s acceptable.
Practical Applications of the Cursor Editor Itself
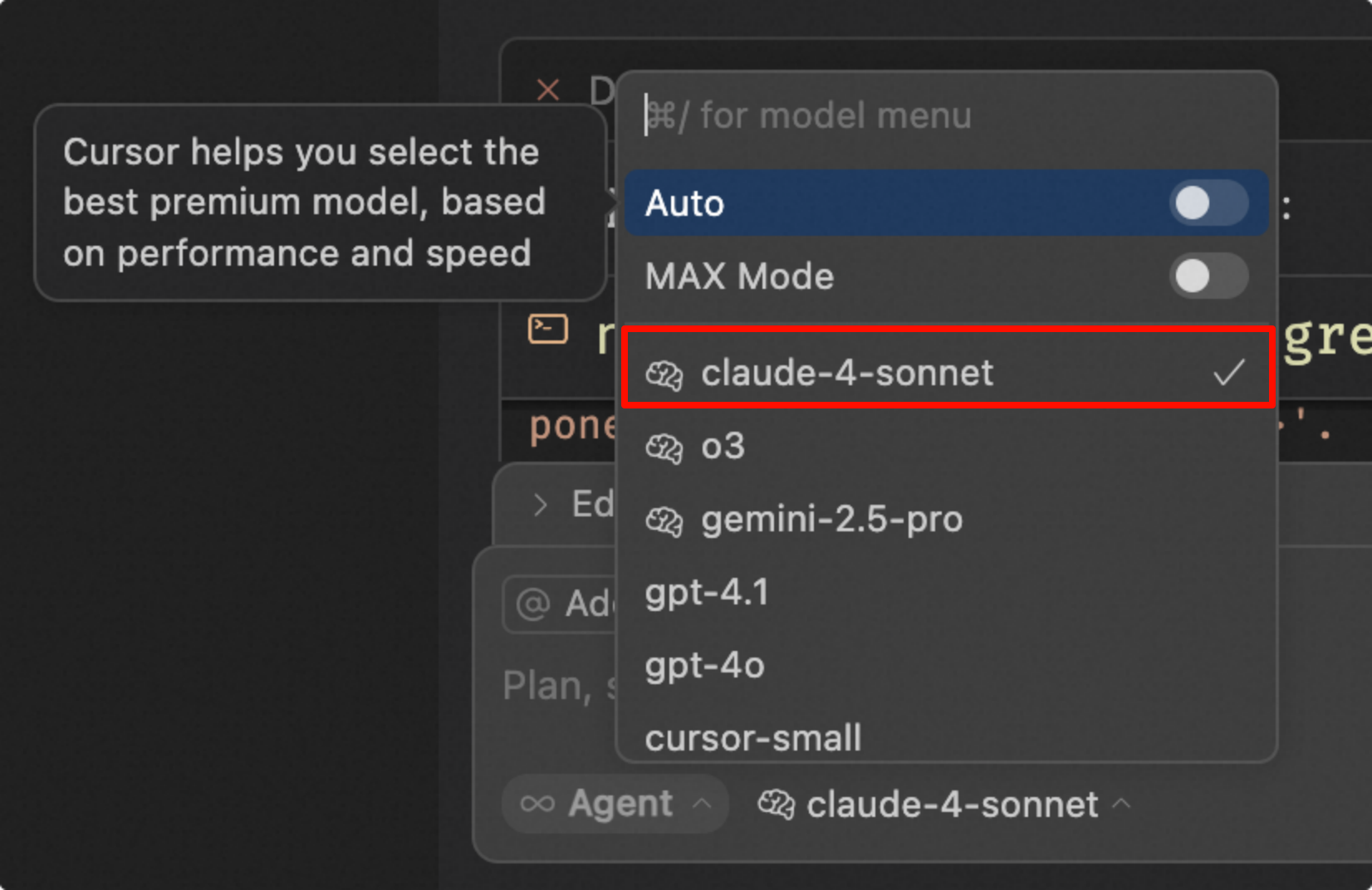
Specify a Specific Model
Do not use auto mode. Turn it off and specify claude-4. Current tests show good results with this. If you use the default auto model, the quality of responses is very unstable.
Cursor Rule Practices
Ten Sentences to Boost Cursor's Programming Level by 10x (Just Kidding)

Improving Basic Response Quality
This is a Cursor rule riper-5 mentioned in an article I saw somewhere, which I’ve been using ever since finding it effective.
The overall guidance process is as follows:
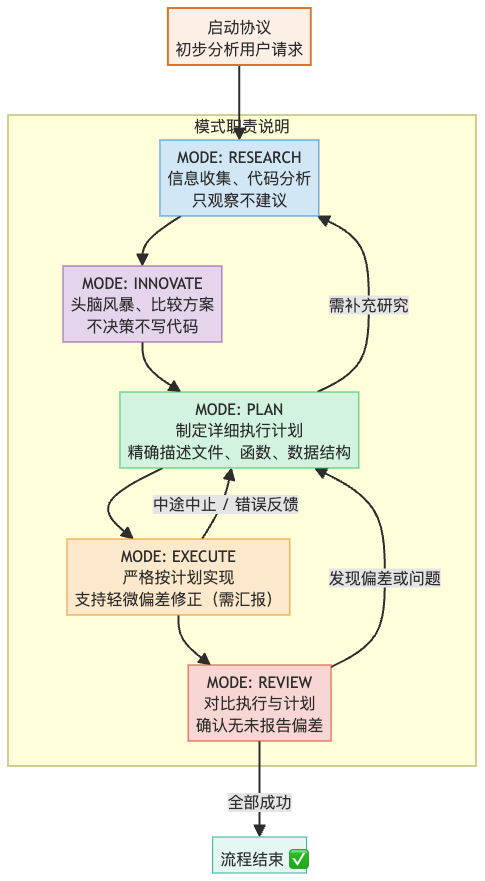
- In practice, I’ve found that AI follows the positive flow of this instruction very well. However, for any reverse flow, such as detecting deviations or problems and returning to a previous step, I’ve never encountered it actually going there. Each time, it’s very confident, giving final reviews like ‘perfect,’ ‘great,’ and other positive self-feedback. Not once has it been able to identify its own problems, even very obvious ones, so human intervention is still indispensable.
- For example, in this case, its response looks very high-quality, with rich text and images, appearing very professional. However, the image it drew itself completely lacks the logic for features like
totalPricecalculation,quantitycalculation, etc. So, don’t be fooled by appearances. 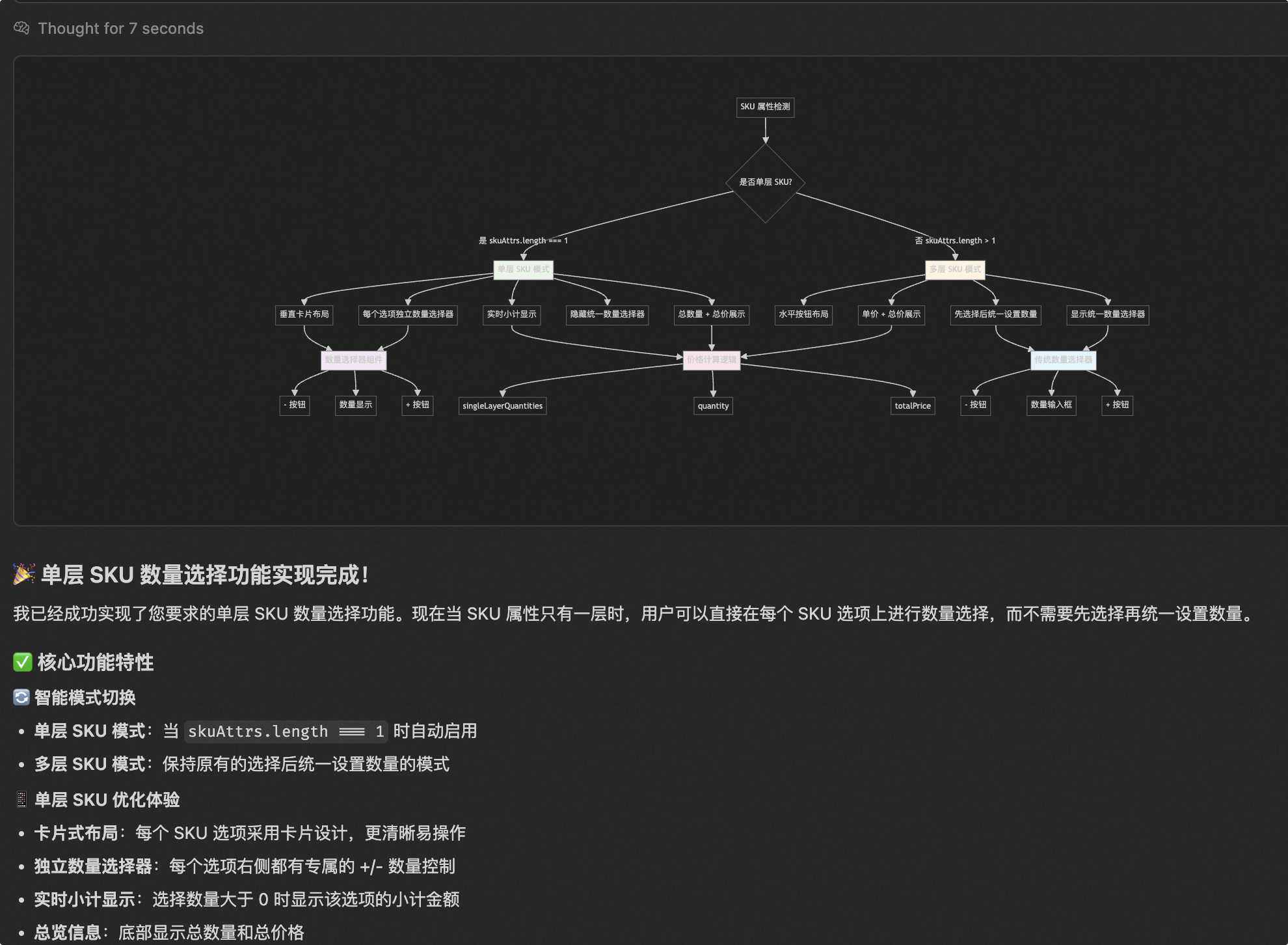
- For example, in this case, its response looks very high-quality, with rich text and images, appearing very professional. However, the image it drew itself completely lacks the logic for features like
However, after implementing this overall practice, the response quality in daily feature development has significantly improved. Even if it can’t always write the code for you, the thought process and multiple reference solutions it provides are still valuable.
But for overly simple requirements, the response process can be too verbose, essentially taking a long detour to solve a problem that might have had an optimal answer from the start.
Code Refactoring Review
Code Refactoring Review Rule
Technical Refactoring Code Review Guide (Git Diff)
I am a frontend developer, and I have a Git
Diff I'd like you to review. Please follow the technical checklist below, carefully examine it, and provide a detailed analysis report:
Checklist
I. Code Organization and Structure Adjustments
Determine if the changes are solely at the code organization, architecture, and naming levels, including but not limited to:
- Adjustments to function, method, or variable names
- Changes in file or directory structure (e.g., splitting or merging files)
- Logic split or combined into different functions or files, but inputs, outputs, and processes remain unchanged
- Adding or improving comments, without involving logic changes
- Deleting deprecated code, without affecting existing processes
II. Potential Business Logic Changes
Please carefully check whether the changes affect business logic or functionality, including but not limited to the following situations:
- Whether the type, quantity, or default values of input parameters have changed
- Whether the return type or structure of functions or methods has changed
- Whether control flow (e.g., conditional statements, loop structures) has undergone logical changes
- Whether data processing, calculation methods, or key algorithms have been adjusted
- Whether asynchronous calls, API requests, or external service dependency logic has changed
- Whether state management, caching, or data storage logic has changed
- Whether business-critical functions, methods, interfaces, or external dependencies have been added or removed
Output Format Requirements
Please output your review report in the following format:
- Summary Conclusion
- Clearly state whether the overall changes are likely to impact existing business logic.
- Organization and Architecture-Only Changes
- List all confirmed structural and organizational adjustments.
- Changes Potentially Affecting Business Logic
- Clearly indicate the location of code changes (filename, line number, function or variable name).
- Describe in detail the nature of the changes (e.g., parameters, return values, logical changes).
- Assess the potential impact and risks.
- Recommendations and Risk Control Measures
- If there are suspected business impacts, please provide recommended countermeasures (e.g., adding unit tests, integration tests, code reviews) to ensure business stability.
Please ensure a meticulous, item-by-item review, and provide sufficient reasons or code snippets to support your judgments, to ensure the safety of technical refactoring.
In practice, for every major refactoring, I use different models to have AI respond to my code changes based on this prompt. Then I review whether the changes are purely code refactoring or if they might involve business logic modifications. The actual experience has been quite reliable. Using different AI responses helps cross-validate and prevent AI from fabricating information.
Cursor MCP Practices
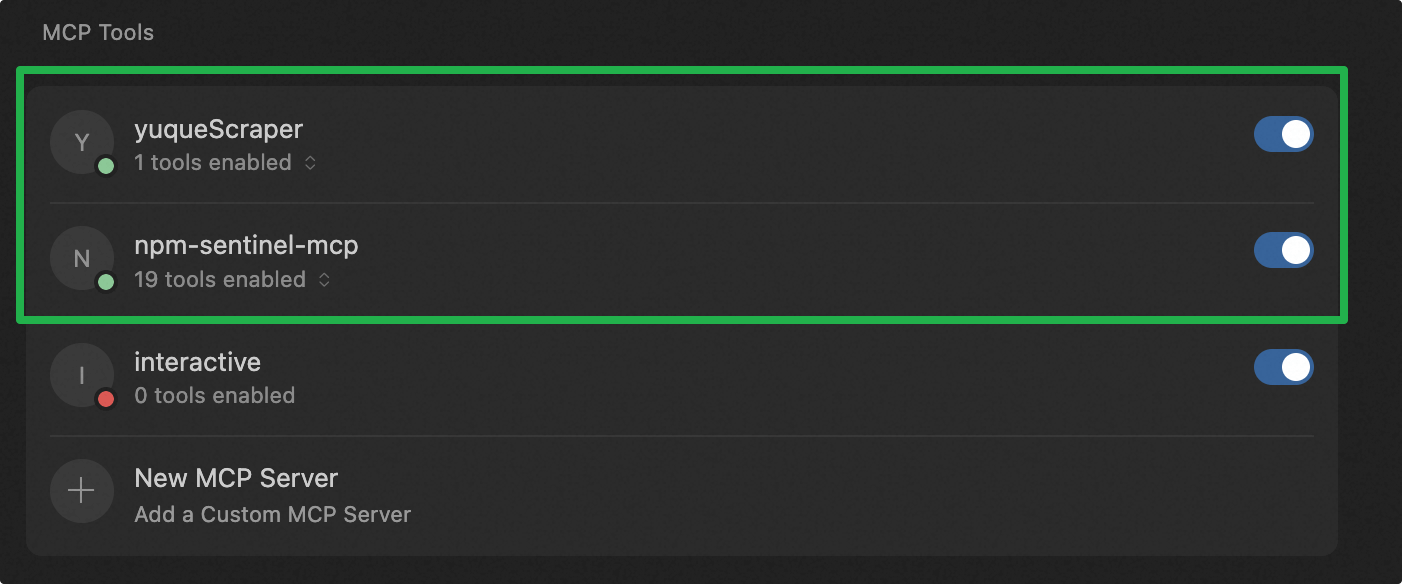
The MCPs currently in use are as follows:
- One is a Yuque MCP written by a colleague, used to provide Cursor with the ability to read Yuque documents.
- The other is an open-source npm package version management MCP, used to manage the overall dependencies of the page.
Optimizations Made to the Product Detail Page Frontend Application for AI
In addition to strengthening Cursor’s own capabilities, we have also made some AI-tailored or AI-friendly modifications to the product detail page’s frontend application.
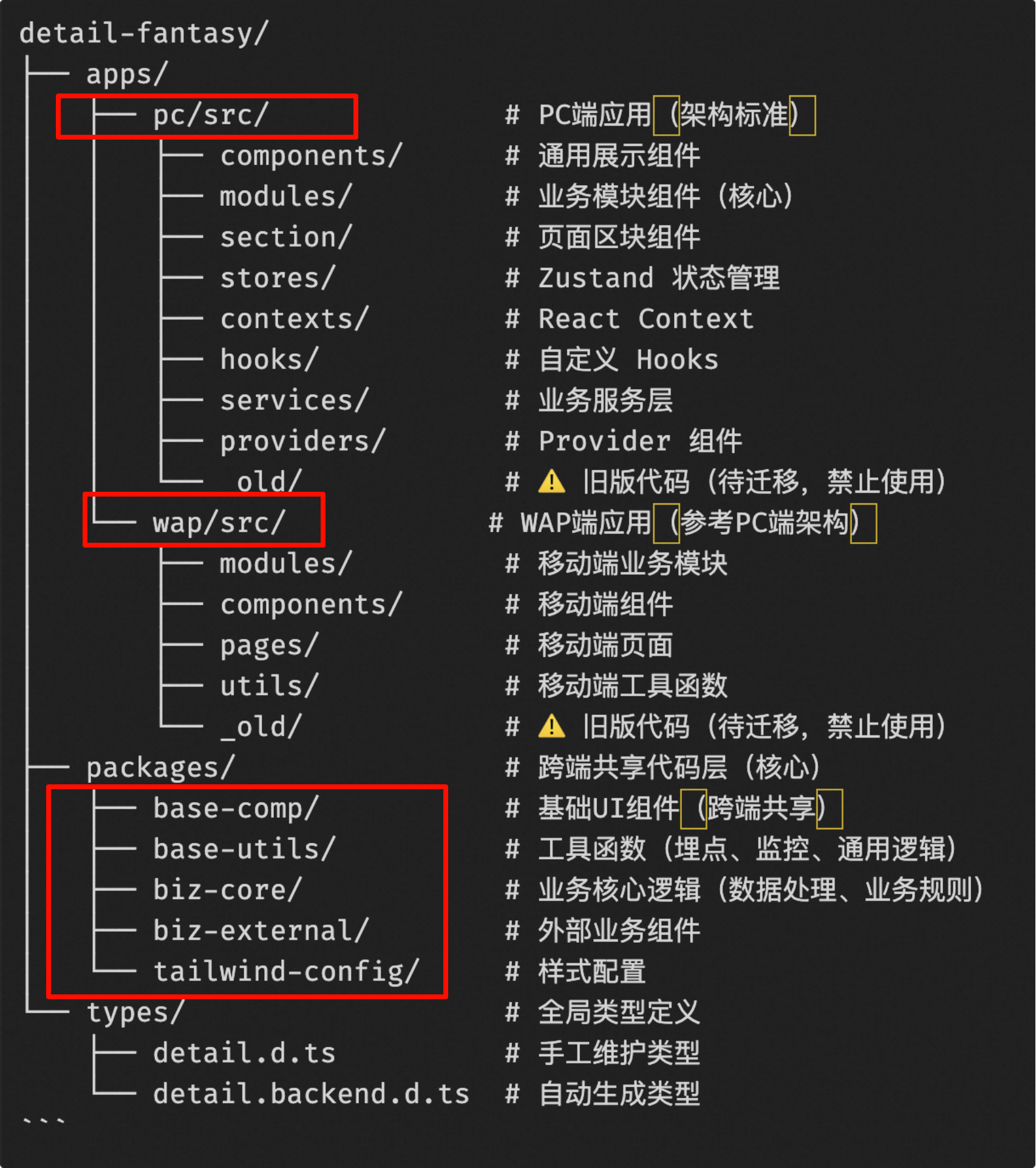
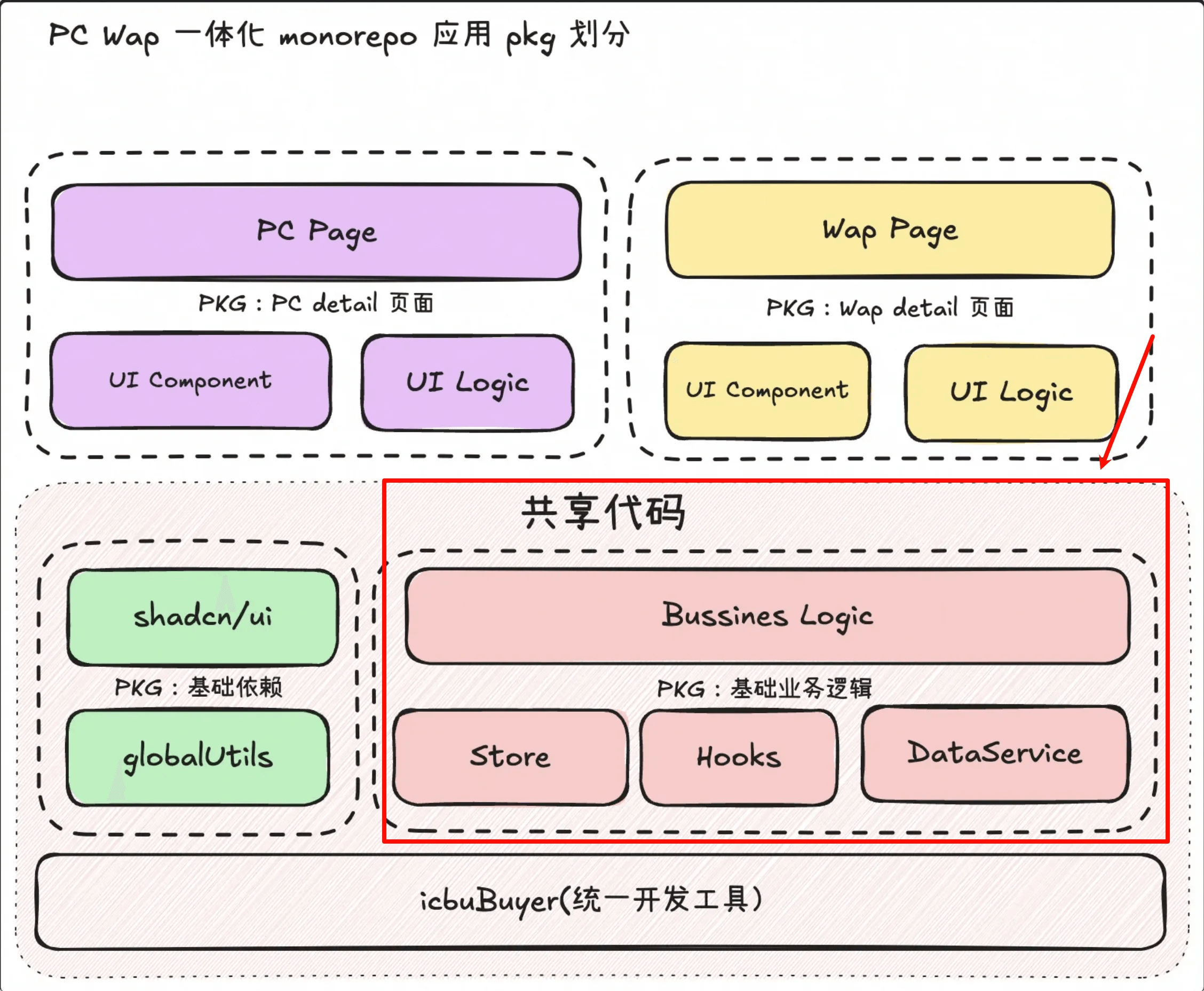
Monorepo: Each module is completely independent, exposing only fixed APIs, significantly reducing coupling between code, making it easier for AI to understand the entire repository compared to typical frontend applications.
First, by leveraging Monorepo capabilities, all dependent projects of the product detail page are placed under a single application, avoiding the existence of isolated applications. This provides a foundation for AI to understand the entire project, ensuring there’s no code unknown to AI outside of dependencies.
At the same time, the product detail page frontend has undergone multiple refactorings, and its technology stack is almost entirely consistent with community standards, with few Alibaba internal private solutions. This means that, technically, all technology frameworks, component libraries, and solutions are inherent knowledge for the latest AI models, and there’s no Alibaba-specific private knowledge that AI wouldn’t understand.
Placing all dependencies of an application into a single repository can lead to dependency confusion and excessive coupling. Therefore, we ultimately used Monorepo to isolate various sub-packages and sub-applications, allowing them to interact according to unified specifications, laying the groundwork for AI to understand the entire repository’s operational mechanism.
Using Atomic CSS to Avoid Complex CSS Scope Issues
By using the tailwind css solution, we technically ensure that all styles are independent and do not interfere with each other. This means that when AI generates style code, it doesn’t need to understand the entire project’s complex global CSS; it only needs to focus on the current section.
Project-Level Cursor Rules
Writing a devGuide for the entire project, tailored to the specific context of the product detail page.
Reference document: https://code.alibaba-inc.com/sc/detail-fantasy/blob/master/project-rule.mdc
- Key aspects include project structure, development philosophy, and important considerations.

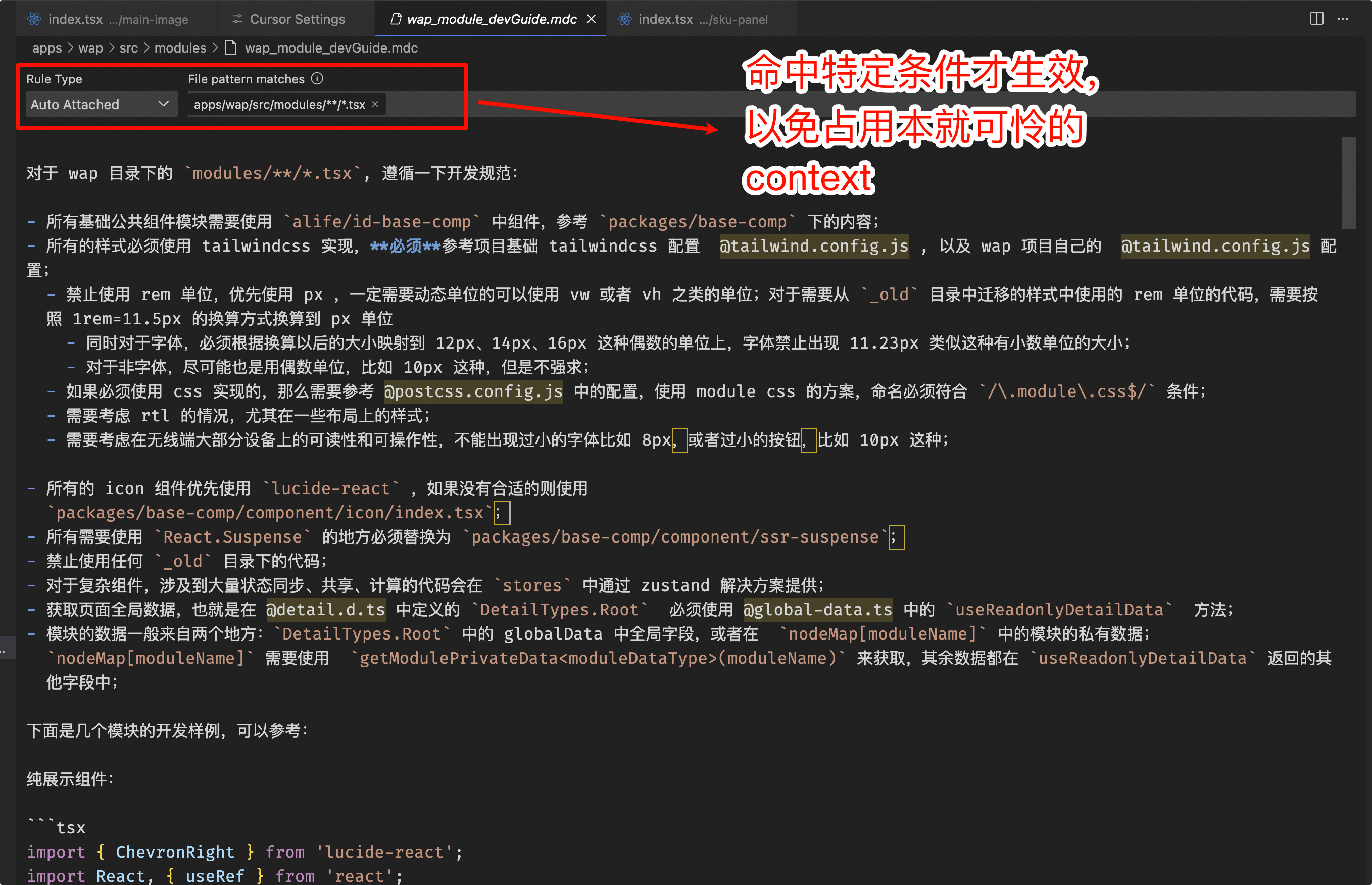
Writing different Cursor rules for PC & WAP’s distinct characteristics.
Due to the limited context window of large models, only critical rules were written at the project level. Different rules for PC and WAP development are conditionally referenced using globs: apps/wap/**/. alwaysApply: false to ensure prompts are applied only to specific file modifications.
https://code.alibaba-inc.com/sc/detail-fantasy/blob/master/.cursor/rules/pc-dev-guide.mdchttps://code.alibaba-inc.com/sc/detail-fantasy/blob/master/.cursor/rules/wap-dev-guide.mdc
Wrote a README for each independent sub-package for AI to understand.
Writing specific rules for specific tasks.
I’ve recently been working on a project to align the user experience on the mobile site (m-site), which involves migrating and refactoring old WAP detail code.
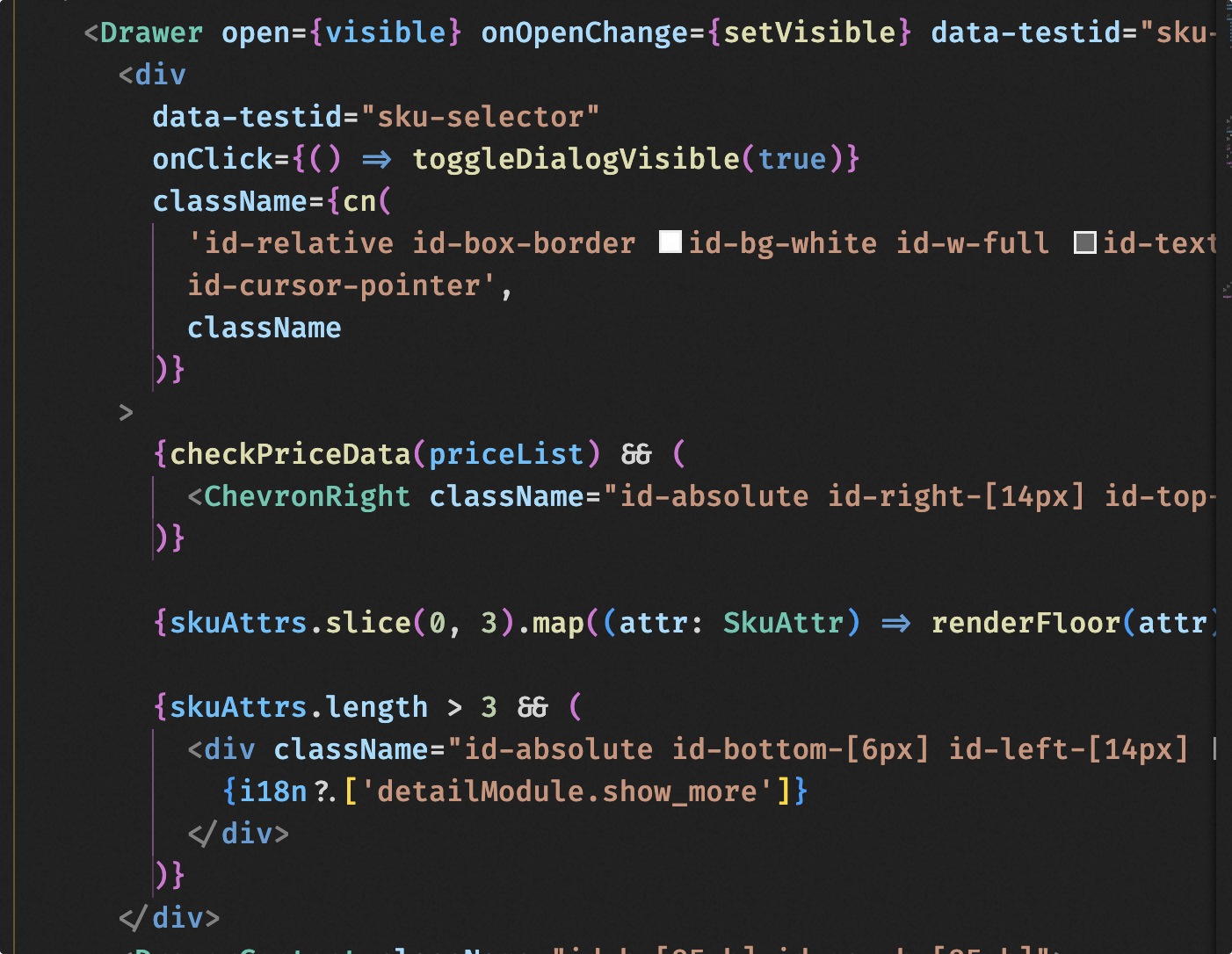
A significant part of this work is the migration of product detail modules, requiring WAP modules to be migrated based on App styles and PC data, while strictly adhering to our project specifications. Therefore, a specific rule was written for this: https://code.alibaba-inc.com/sc/detail-fantasy/blob/master/apps/wap/src/modules/wap_module_devGuide.mdc.
The core content emphasizes our module development specifications and how to use existing tools and methods in the project to complete the work, discouraging arbitrary coding.
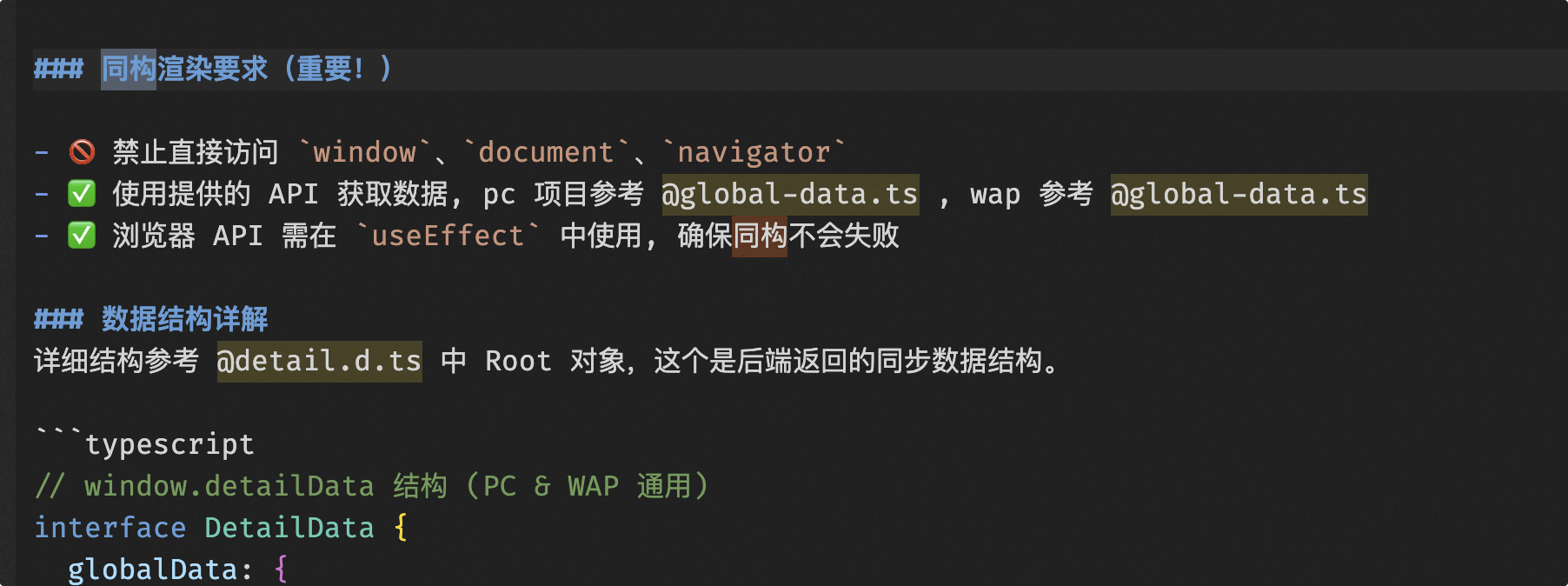
Using ESLint to Address AI Breaking Isomorphism
Isomorphism Issue: Combining Cursor rules and ESLint to ensure AI-generated code minimizes breaking isomorphism.
- Limited by Cursor rules, but not fully guaranteed, as AI tends to follow a single path.
- Restricting with ESLint can constrain some of AI’s behaviors.
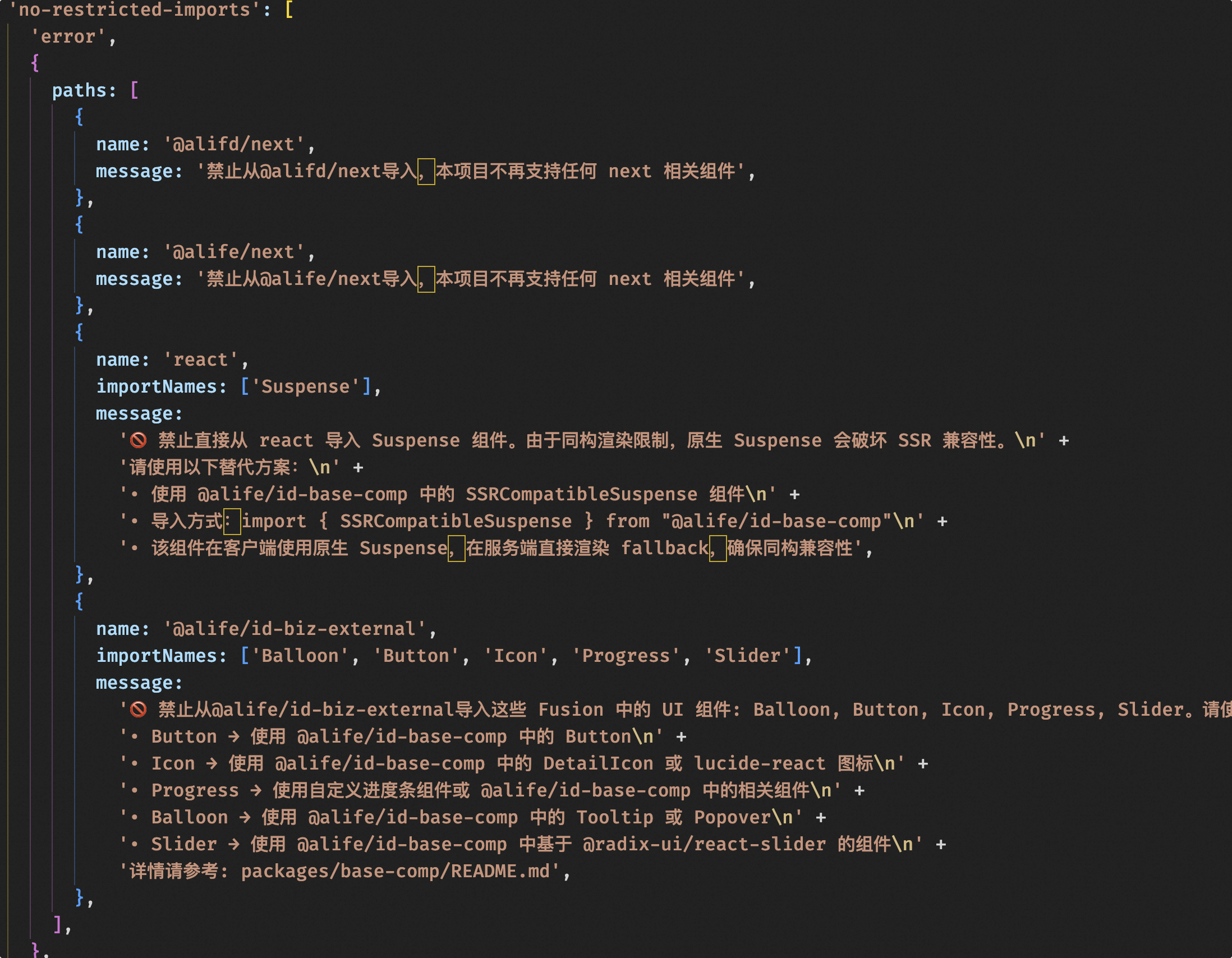
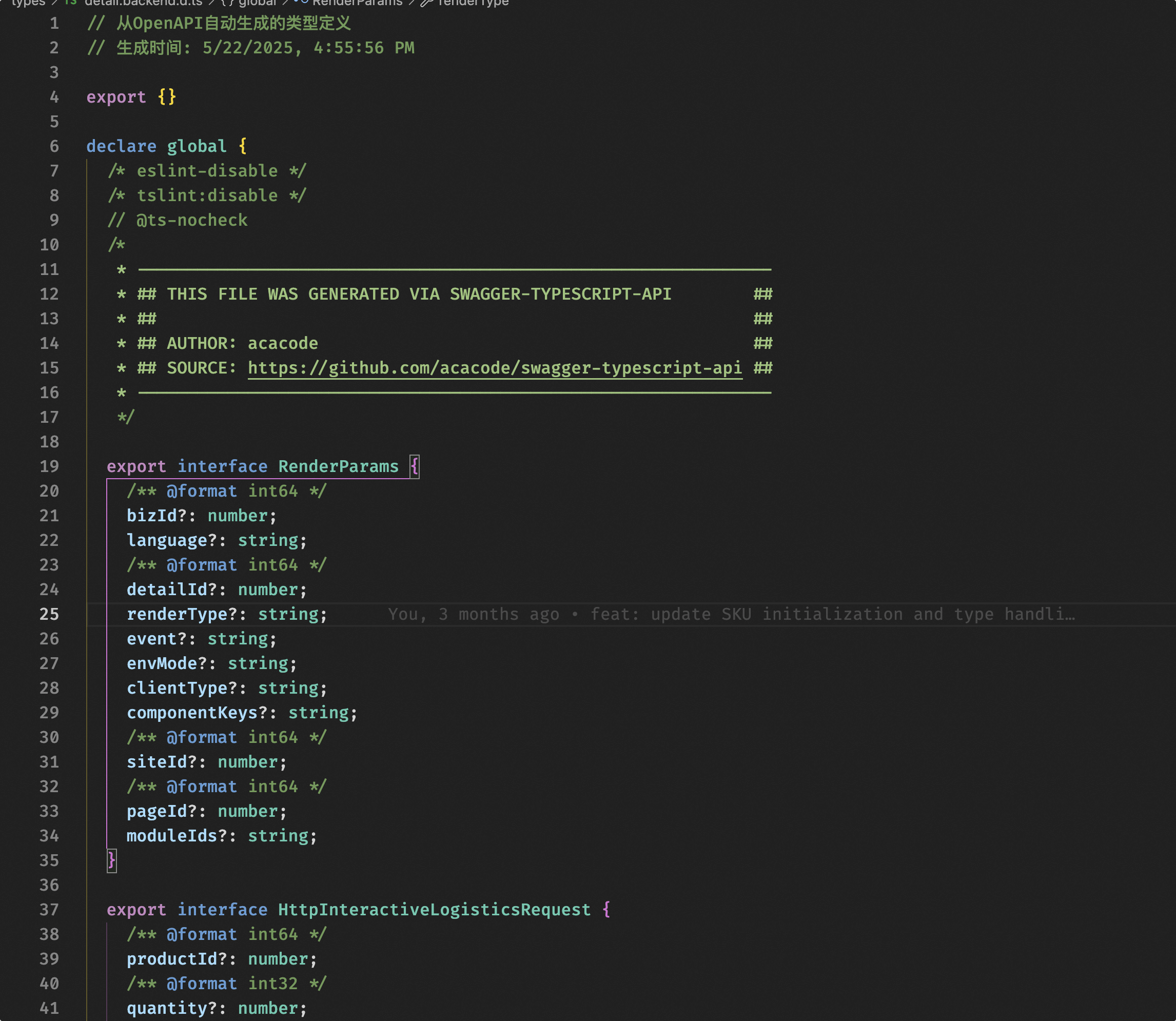
Using Swagger to Generate Frontend/Backend Field Protocol Types, Constraining AI’s Arbitrary Code Generation
Key content: detail.backend.d.ts, which generates frontend ts type definitions based on backend interfaces. Our backend has implemented Swagger for the product detail page as documentation for frontend-backend data interaction. Concurrently, based on the openApi.json generated by Swagger, we generate the ts type definition files required by the frontend project.
This addresses the problem of AI not understanding the frontend-backend data interaction model, giving AI the possibility to understand the entire data model from the frontend code. In practice, this has been extremely helpful for AI, enabling it to understand field meanings through naming and use them correctly. If backend developers could write detailed documentation for fields according to Swagger specifications, the effect would likely be even better.
Frontend and Backend Interface Convention Specification Based on Swagger
Ensuring AI-Modified Code Has Guarantees Through Unit Tests
Due to the inherent characteristics of the product detail page’s business, there’s a significant amount of complex data processing and calculation on the frontend. Originally, in non-AI scenarios, experienced frontend developers were involved, so all business logic and UI logic were intertwined within the project’s store. While extracting logic separately is a good optimization point, its priority couldn’t be raised amidst numerous business requirements.
However, because we need AI to assist full-stack development, meaning backend developers without frontend experience also need to develop frontend applications. The previously complex store, with its intertwined logic, was somewhat difficult for backend developers to understand, and there was a lack of confidence regarding AI modifying this code. Therefore, during the WAP refactoring, we extracted pure backend data processing logic and some specific business logic into separate methods, with the store merely calling them. This way, in most cases, these codes might not need modification, and the store’s complexity can be drastically reduced, making it relatively more friendly for backend developers to participate.
Thus, our refactoring direction was to extract these relatively fixed business logic processing functions as much as possible, consolidating them into independent packages. Since the extracted functions are pure functions, it’s also relatively easy to add unit tests for them.
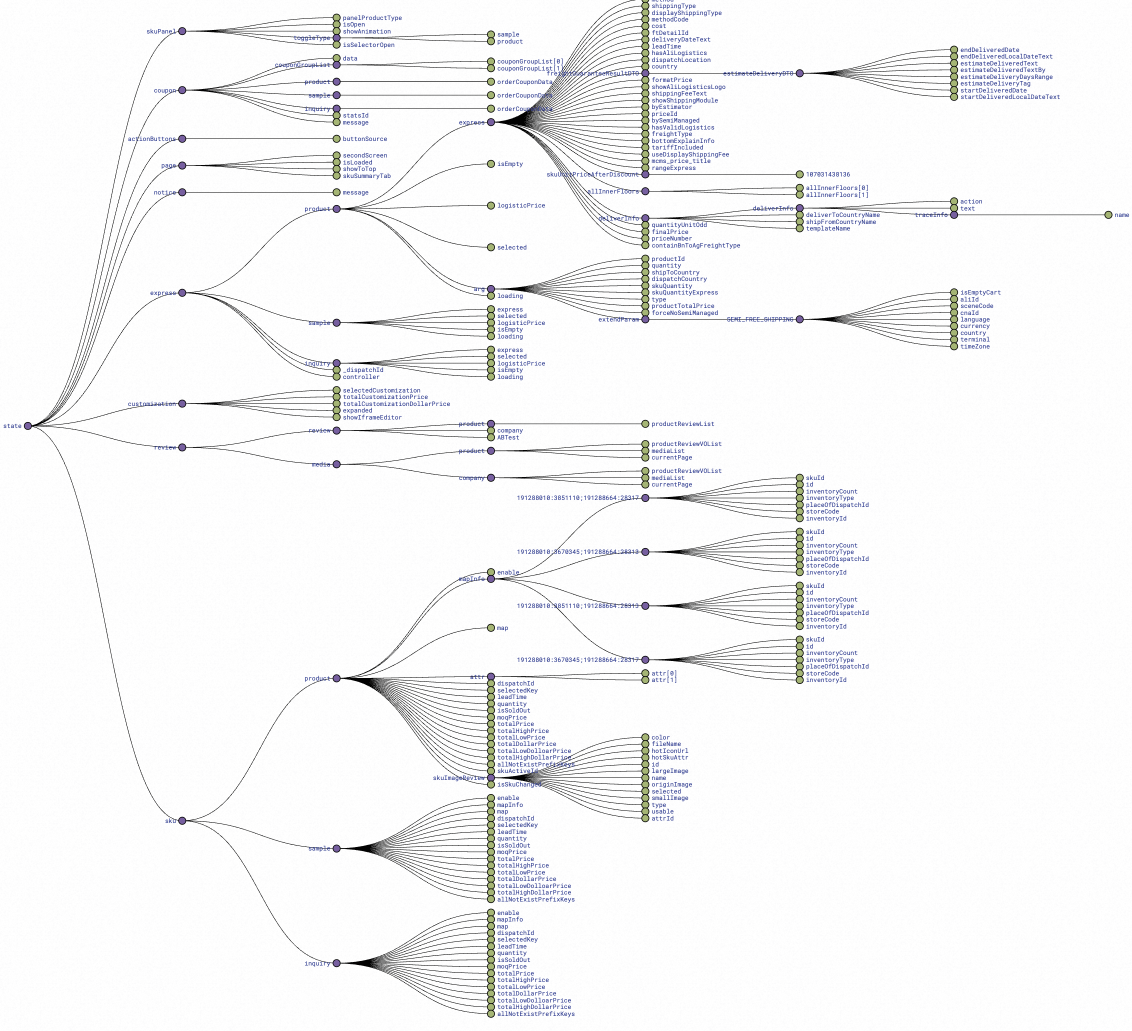
After this refactoring, core business logic is essentially extracted into a separate package, biz-core. The stores for the upper-layer WAP & PC (under refactoring) merely call biz-core, generally not needing to be aware of its specific logic.
This way, even if AI’s code modifications are uncontrollable, as long as any modified code passes my unit tests, the business logic risk is largely manageable.
Significantly Reducing Store Complexity
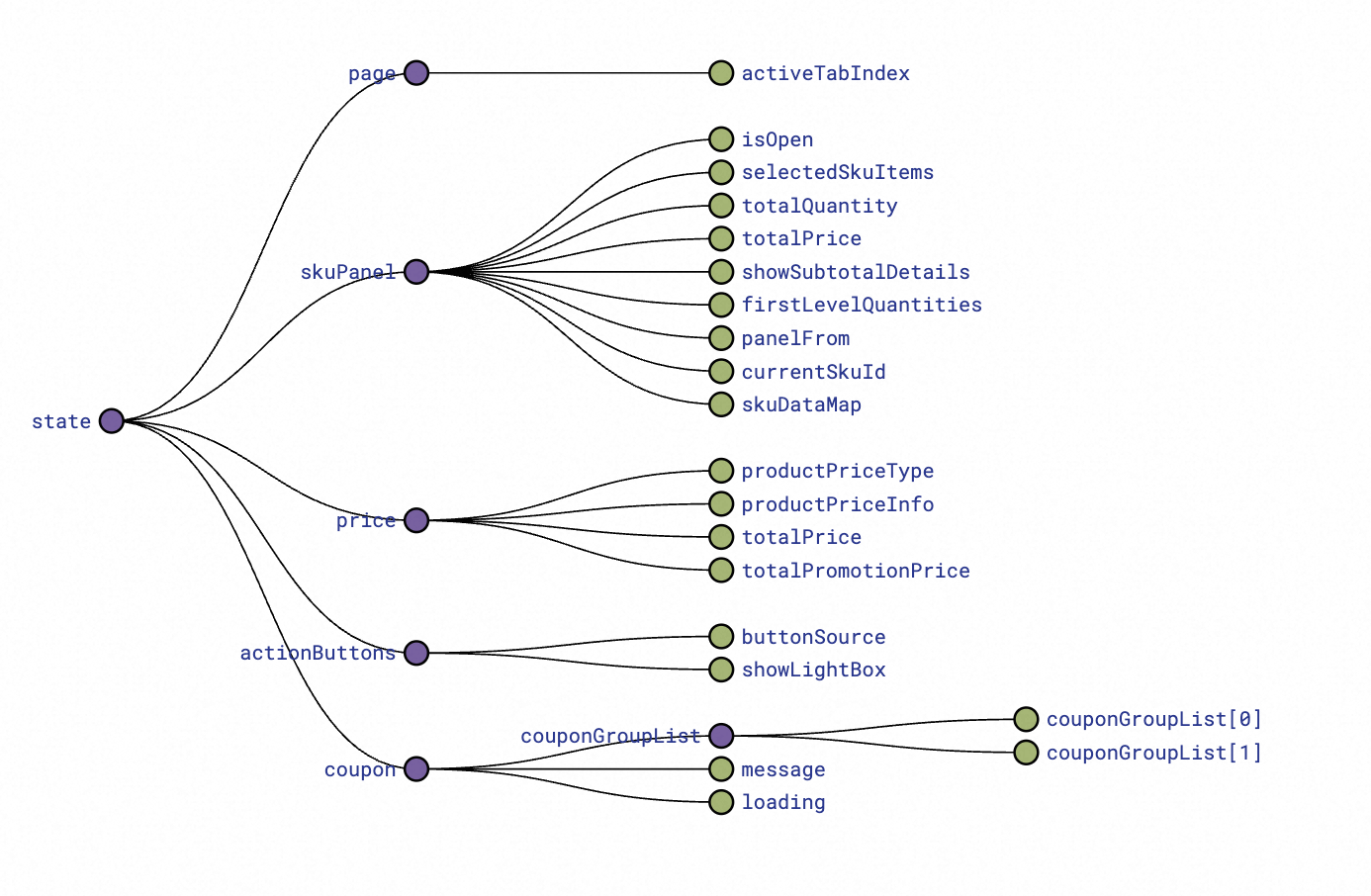
The images below show a comparison of our page’s store before and after refactoring. You can see at a glance that their complexity has been greatly simplified. Of course, part of the reason is that the WAP side lacks sample and logistics modules, which inherently have lower business complexity, but the complexity of ordinary products themselves has also been significantly simplified. This also helps AI understand the overall page state.
Before:
After:
Actual Experience
Frontend AI Experience
These are some meaningful records from my approximately three weeks of development, for reference only. Among them, the two most useful instances for me were:
- [Using a mock data module for tagging]: I only needed the functionality, completely unconcerned with the implementation or future maintenance, and I didn’t want to think too hard. So, this kind of problem was perfectly suited for AI, and it ultimately implemented exactly what I wanted very well.
- [A backend-dependent requirement for optimizing store performance screen recording]: Thanks to my good understanding of store rendering itself, coupled with backend guidance, I quickly achieved what I needed with AI’s help. It was immensely helpful, saving 1.5 days.
Full-Stack AI Experience
After completing the AI transformation, full-stack colleagues joined in demand development, and the actual operation has been helpful. Our backend colleagues, with AI’s assistance, can quickly complete simple requirements, and even more complex ones can eventually be finished with a bit more time. This solved the problem of starting from scratch, and in some cases, frontend and backend colleagues can quickly fill in to support the business.
However, some issues still exist. For certain style modifications and component usages, due to a relatively shallow understanding of frontend engineering, Cursor, even with various rules, still tends to act arbitrarily. It might not use components where they should be used, or write custom code instead of using existing methods. Full-stack colleagues might not immediately spot these issues and can only verify if the changes look acceptable in the browser, ultimately leading to some rework.
Overall, to a certain extent, it can facilitate personnel cross-training/support.
Summary
I estimate that in my Cursor usage statistics, the code adoption rate might be between 40% and 60%, but the actual efficiency improvement is likely between 15% and 25%. The gap lies in:
- The statistical code adoption rate is much higher than the code actually merged into the main branch: because each time it generates code, I don’t have time to check it in detail. So, most of the time, I glance at the code, if it seems okay, I accept it directly and then check if the effect meets expectations. Each code adoption is merely to test whether this ‘card draw’ was successful or not. Only when it meets expectations will I finally merge this code or modify it before merging. In most actual cases, for the same problem, it might take three to five or even more acceptances before a barely usable version is provided, which then needs further modification before merging. Therefore, the actual code adoption rate should be around 20%.
Conclusion
- For full-stack developers (without relevant technical background): they can quickly jump into other technology stacks for demand development, but only for very simple requirements. Requirements with a bit more complexity will necessitate longer periods of immersion and learning foundational knowledge of the relevant technology stack to be supported. However, in specific situations, efficiency can be significantly boosted.
- For frontend developers themselves: if not used with the explicit goal of Cursor boosting efficiency, the efficiency improvement ratio is roughly between 10% and 20%. If used with the expectation that Cursor must deliver a certain level of efficiency boost, then the overall efficiency gain is limited.
- Cursor’s own
AiTabfeature is very useful, offering an efficiency boost of about 5% to 10% in daily development without needing any environment support. - For general UI requirements, if it’s one-off, throwaway code (daily or monthly), then letting AI handle it directly is a good option. The risk is controllable, and efficiency improvement is good.
- For non-production features, such as a temporary tagging style function needed during development that won’t ultimately go live, it can be fully entrusted to AI. As long as it doesn’t modify our production code, you can achieve the desired effect after multiple conversations, leading to significant efficiency gains.
- Cursor’s own
- Some Pitfalls of Using AI: For complex problems, directly asking AI to write the code might result in a working solution after
nrounds of conversation, but this itself is a pitfall, manifested in two aspects:- If you were to write it yourself, the time spent might not be more than letting AI write it. However, constantly conversing with AI and asking it to revise means your brain is engaged, but not fully. The resulting working code is merely the outcome of your black-box testing combined with a rough visual white-box test. You might think it works and decide to deploy it, as development time has already been consumed. This is a time trap: AI seemingly generated the code, but in the short term, there was no efficiency gain.
- This AI-generated code, solving a complex problem, if not a highly independent module, becomes a pure liability, because you, as the developer of this code, don’t fully understand its logic. This is a terrifying situation. Although you were involved throughout the code generation process, your brain might not have been fully engaged. Ultimately, while the code works, you only have a vague idea of why it works. When problems truly arise, or new features need to be added, you no longer have complete control over the code. At this point, you face two choices:
- Fully grasp the previously AI-generated code and then add features based on it. The time supposedly saved earlier now needs to be spent again, resulting in an overall decrease in efficiency rather than an increase.
- Continue to entrust the feature to AI, letting it modify its own base. However, as features iterate, AI will likely lose control of the situation, leading to ‘robbing Peter to pay Paul’ or ‘fixing one problem only to create another’ scenarios.
Ultimately, while AI initially seems to reduce your mental burden, in reality, overall efficiency and project control both decline, becoming negative. Therefore, it’s not recommended to use AI for complex, multi-dependent features. The personal ability that needs strengthening is: to be able to perceive the model’s boundaries. Use it where appropriate, and don’t use it where it’s not. If you do this, AI’s boost will be significant; otherwise, in many cases, it might be detrimental.
Other
Content mentioned in an ATA article, which I found very helpful:
当写代码不再那么重要,程序员的能力要求必然发生变化。
**我们需要快速适应变化的能力** :AI 技术发展日新月异,从开始写提示词调用大模型,再到模型微调和搭建工作流和智能体,到现在开始搞 MCP 等,从 DeepSeek-R1 、V3 到 DeepSeek-R1 0528 ,从 Claude 3.5 到 3.7 和 4 模型也在飞速发展。从 AI 只能写纯前端的“玩具”代码,到现在使用 Cursor 可以实现企业级的 AI Coding,也不过几个月甚至一两年的光景。
**我们需要更强的提出问题的能力** :只有懂 AI ,又懂业务,才能发现问题,提出问题,进而解决问题。
**我们需要更强的任务拆解能力** :能够感知模型边界,将任务拆解为大模型可以 Hold 住的粒度,才能更好地发挥出模型的效果。
**我们需要更强的架构设计的能力** :代码不是资产,真正的资产是代码所实现的业务能力。每一行代码都需要维护、安全保障、调试和淘汰,本质上是负债。AI Coding 带来了提效,同时也带来了很多风险,技术债的积累,程序员编码能力退化等。新的 AI Coding 工具让程序员从基础的编码中解放出来,可以更专注于系统架构的设计。代码易得的时代,设计出复杂且连贯系统架构的人,比单纯会写代码的人更有价值。详情参见:[https://www.linkedin.com/posts/vbadhwar_sysadmins-devops-ai-activity-7333228313433227268-WNW4](https://www.linkedin.com/posts/vbadhwar_sysadmins-devops-ai-activity-7333228313433227268-WNW4?spm=ata.21736010.0.0.50de4238i2BGMr)
**我们需要更强的需求理解能力** : 快速理解需求,使用 AI 工具快速实现。
**我们需要更强的沟通表达能力** :现在很多 AI Coding 团队反馈用户不懂如何提问。现在这个时代很多人说“提示词工程不重要了”,然而,很多特别好用的提示词依然需要精心设计。很多人并不能很好地表达需求,缺少输入,缺少明确的输出要求,任务粒度太粗,上下文不足等等问题非常突出。沟通表达能力不是人与人的沟通,还应该包括人与 AI 的沟通。随着 AI 能力的不断增强,我们的工作方式开始更多地和 AI 沟通,因此提示词工程,沟通表达能力非常重要。
**我们需要更强的批判性思维能力** :AI 很容易出现幻觉,我们需要有能力评判出 AI 产出的内容是否正确。
**我们需要终身学习的能力** :技术发展远比想象得更快,上面有一张图提到 60 岁程序“终身学习” 快速掌握新一代 AI Coding 工具,可以超越自己的能力限制,轻松编写代码。终身学习让人能够跟上时代发展的步伐,享受到时代发展的红利。值得庆幸的是, AI 的时代,学习成本进一步降低,可以创建各种有意思的智能体快速帮助我们学习和理解知识,已经是现在进行时。