
流式渲染
首先, 简单介绍一下什么是流式渲染. 流式渲染是利用 http1.1 的分块传输编码的特性, 让服务端分块返回 html , 浏览器可以在接收时逐步渲染页面, 这样有助于页面的首屏展现, 提升用户体验.
分块传输编码
分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制,允许 HTTP 由网页服务器发送给客户端应用( 通常是网页浏览器)的数据可以分成多个部分。分块传输编码只在 HTTP 协议 1.1 版本(HTTP/1.1)中提供。
分块传输格式
如果一个 HTTP 消息(包括客户端发送的请求消息或服务器返回的应答消息)的 Transfer-Encoding 消息头的值为 chunked,那么,消息体由数量未定的块组成,并以最后一个大小为 0 的块为结束。 每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个 CRLF (回车及换行),然后是数据本身,最后块 CRLF 结束。在一些实现中,块大小和 CRLF 之间填充有白空格(0x20)。 最后一块是单行,由块大小(0),一些可选的填充白空格,以及 CRLF。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。 消息最后以 CRLF 结尾。
一个栗子
店铺无线和 PC 端都做了流式渲染的改造, 首屏提升都在 200ms 左右, 而且业务数据也都有相应的提升 。
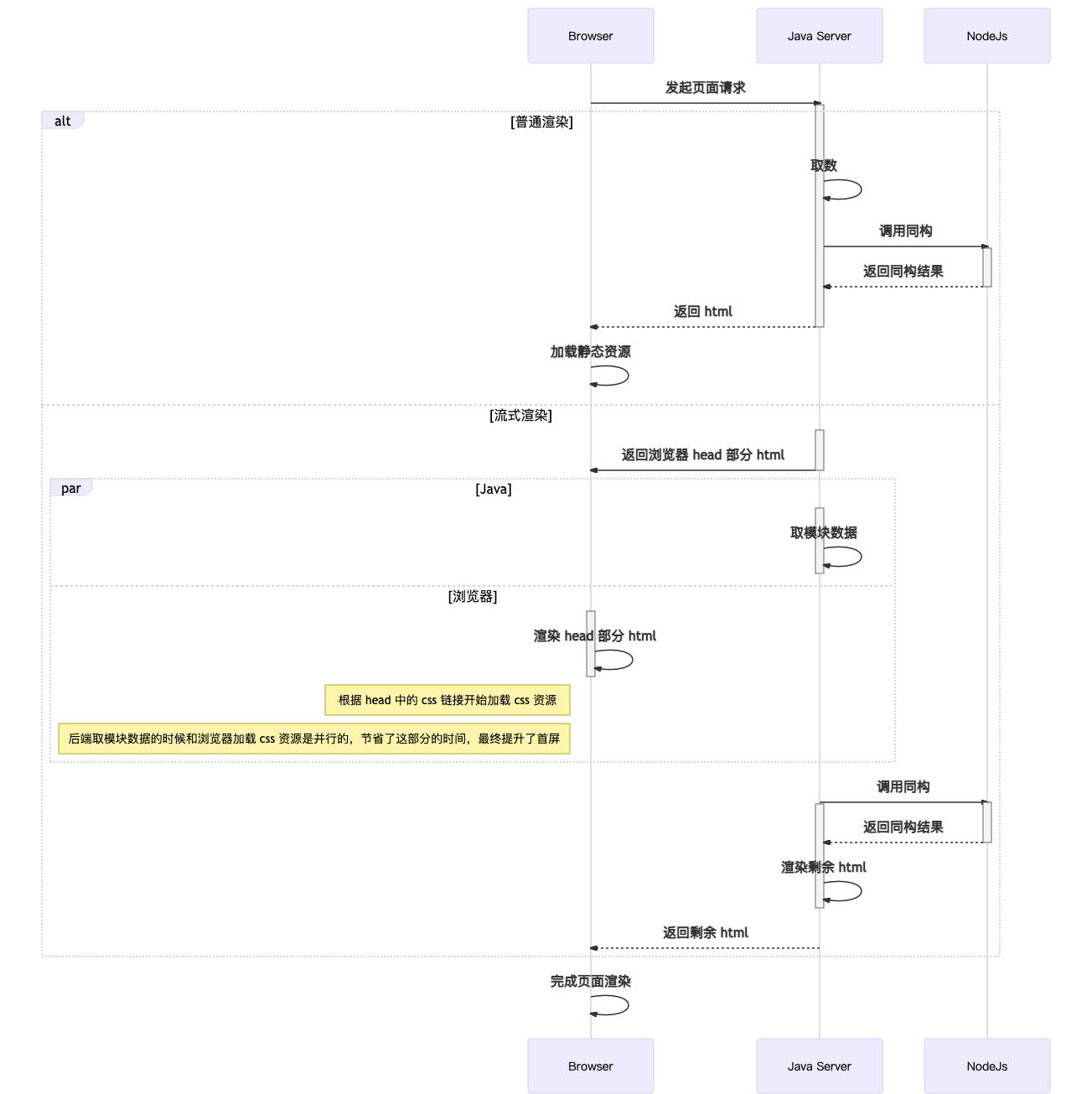
店铺普通渲染和流式渲染对比时序图:
工程化解决方法 Spark
流式渲染的好处很明显,但每个应用接起来还是有一定的成本,我就打算从店铺的改造思路中抽离一个可以快速接入流式渲染的方案。
方案预研
流式渲染本身很是很简单的,就是后端分端吐 html 就好了。问题是如何高效的让业务开发无痛的接入,一开始想了几个方案,在周会上和组里过了一下:
方案 a
提供一个中间件或者插件, 在其中实现流式渲染的相关逻辑.
调用方接入中间件, 并采用人工定义配置的方式, 来实现模板和数据的关联, 然后服务端(Node or Java) 根据配置来流式渲染页面.
以 egg.js 举例:
xxx Controller {
test() {
// spark 为流式渲染中间件挂载在 ctx 上的方法
const pipe = this.ctx.spark();
this.ctx.body = pipe;
// 设置分块渲染的配置
pipe.setPageConfig([{
tpl: 'admin/index-pipe/pipe-1.nj',
getData: (ctx) => Promise.resolve(mergerCommonContext({}, ctx)),
}, {
tpl: 'admin/index-pipe/pipe-2.nj',
getData: ctx => bindGetPageData(ctx),
}]);
// 调用流式渲染方法
pipe.render()
}
}优点:
- 实现成本低
- 业务侵入较小: 不需要动业务逻辑
缺点:
- 需要对模板进行拆分
方案 b
通过对模板进行约定方式来实现页面的分块, 然后在服务端渲染模板时, 根据模板分块的内容去插入数据, 实现分块渲染.
举例: 模板
<!-- spark:start block0 -->
<!doctype html>
<html>
<head>
<title>Test</title>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="renderer" content="webkit" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<link
rel="shortcut icon"
href="//is.alicdn.com/favicon.ico"
type="image/x-icon"
/>
</head>
<body>
<!-- spark:end block0 -->
<!-- spark:start block1 -->
<div style="width: 100%">
{% for item in pageData %}
<img
src="http://design3d-zhangbei.oss-cn-zhangjiakou.aliyuncs.com/{{ item.thumbnailOssKey }}"
style="
width: 200px;
height: 200px;
display: inline-block;
vertical-align: top;
"
/>
{% endfor %}
</div>
<!-- spark:end block1 -->
<!-- spark:start block2 -->
<div style="width: 100%">
{% for item in pageData %}
<img
src="http://design3d-zhangbei.oss-cn-zhangjiakou.aliyuncs.com/{{ item.thumbnailOssKey }}"
style="
width: 200px;
height: 200px;
display: inline-block;
vertical-align: top;
"
/>
{% endfor %}
</div>
<!-- spark:end block2 -->
<!-- spark:start block3 -->
<script>
window._PAGE_DATA_ = {{ pageData | default({}) | dump | replace(r/<\/script/ig, '<\\\/script') | safe }};
</script>
</body>
</html>
<!-- spark:start block3 -->服务端调用:
xxx Controller {
test() {
// spark 为流式渲染中间件挂载在 ctx 上的方法
const pipe = this.ctx.spark();
this.ctx.body = pipe;
// 设置分块渲染的配置
pipe.renderBlock( 'block0', {xxx})
pipe.renderBlock( 'block1', {xxx})
pipe.renderBlock( 'block2', {xxx})
pipe.renderBlock( 'block3', {xxx})
}
}bigPipe
流式渲染还是要依赖服务端的返回顺序, 当有多个页面块要取数渲染时需要串行调用返回. 如果在流式渲染的基础上再往前进一步就是 bigPipe 了, 不需要依赖后端的返回顺序. 哪一块取数完毕渲染好了, 就把哪一块 html 返回给浏览器渲染.
原理非常简单, 服务端首先返回页面的 layout . 然后每个页面 block 渲染好后, 以 script 标签的形式返回给浏览器, 比如:
<script>
spark.render("#id", "<div>page1</div>");
</script>通过和前端约定好的方法, 来通过 js 往页面的特定部位插入 html 实现页面的渐进式渲染. 优点:
- 可以不按照 html 来更快返回内容供浏览器渲染 缺点:
- js 插入的 html 中的内联 script 标签中的 js 不会执行. 比如下面这个 onclick 事件就不会触发:
<script>
spark.render('#id', '<div>page1<script>console.log(123)</script></div>');
</script>- 需要把 script 标签的内容单独拎出来
eval一下才能执行. - 需要侵入前端代码: 由于页面乱序返回, 所以原本依赖 script 插入顺序来保证运行的先后机制就可能失效了, 需要通过事件或其他方式来通知页面的渲染情况来保证 js 运行顺序, 增加复杂度
结论
和同事过下来,得到的建议主要为一下几点:
- 虽然在 AB 两个方案中,大家更加倾向于 B ,因为不用分割多个模板,但依然对需要改动到模板本身有抵触
- 对于有些业务是存在多个业务场景用一个模板作为 layout 的情况,如果需要不同的页面分割情况,那么方案 B 存在问题
- 对 bigPiep 的诉求不强,因为提升有限但成本相对提升很多
在这些意见的基础上,对原有的方案作了一下改进:
- 模板不需要关心是否被流式渲染页面用了
- 去除后续对 bigPipe 的支持
最终方案如下: 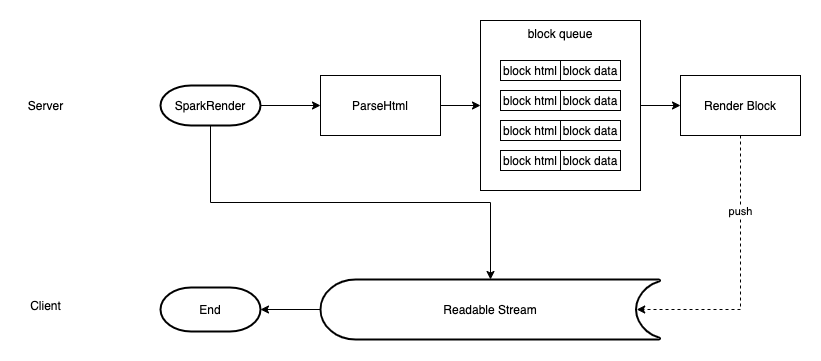
- 首先调用插件提供的 SparkRender 方法,传入 regList 和 dataList,立即返回一个 Readable Stream 给浏览器
- 根据 regList 对 html 进行切分,然后和 dataList 组成一个待渲染的 blockQueue
- 根据 blockQueue 的顺序,串行调用 RenderBlock 方法,并将渲染的结果 push 到 Readable Stream 中
- 当 blockQueue 渲染完毕时,关闭流,整个流式渲染进程结束
支持情况
目前仅支持基于 egg.js 的 node 应用。
适用场景
所有对性能有追求的需要后端进行模板渲染的场景。
如何使用
对于一个基于 egg.js 的 node 应用,只需要两步即可完成接入:
- 在应用中引入并打开
egg-spark插件:
tnpm install egg-spark在 `config/plugin.js` 中开启插件
exports.spark = {
enable: true,
package: 'egg-spark',
};- 对要开启流式渲染页面的 controller 做一些微小的修改:即将原有的 render 方法替换为 spark 插件提供的 render :
spark.render(tpl, regList, dataList):void
入参:
| 参数 | 类型 | 含义 |
|---|---|---|
| tplPath | string | 要渲染的模板地址,和框架提供的参数含义相同,不用修改 |
| regList | reg[] | 用来切分页面的正则列表,根据 regList 的长度将页面切分为 regList.length+1 份。每次切分会以当前正则匹配到第一个字符作为基准 |
| dataList | object[] / function[] | 根据 regList 切分的页面块,来传入对应的渲染模板需要的数据。可以直接传入数据的 object ,也可以传入同步或者异步的数据方法 |
举例:
//原代码:
this.ctx.render("admin/index.nj", mergerCommonContext({ pageData }, this.ctx));
//修改后代码:
this.ctx.spark.render("admin/index.nj", {
// regList 是一个用来切分页面的正则列表,根据 regList 的长度将页面切分为 regList.length+1 份
regList: [/id="root"/],
// dataList:根据 regList 切分的页面块,来传入对应的渲染模板需要的数据。可以传入数据 object ,也可以传入同步或者异步的数据方法
dataList: [
mergerCommonContext({}, this.ctx),
async () => getPageData.call(this),
],
});这样你的页面就已经支持流式渲染了,是的,就这么简单。
最佳实践
一般情况下,一个页面只需要拆分为两块就好:
- 先返回包含页面
css标签的<head>部分,这样浏览器就可以开始加载并解析css资源 - 与此同时,后端开始进行取数等其他耗时较长的操作
拿刚上线的定制页面举例,实际的看一下如何通过 Spark 接入流式渲染。这是定制管理后台的模板 admin/index.nj :
<!doctype html>
<html>
<head>
<script>
window._customizePerfTimeTTfb = Date.now();
</script>
...
<link
rel="shortcut icon"
href="//is.alicdn.com/favicon.ico"
type="image/x-icon"
/>
{% block cssContents %}
<link rel="stylesheet" href="{{cssFile}}" />
{% endblock %}
<script>
window._customizePerfTimeCss = Date.now();
</script>
</head>
<body data-spm="customize" class="{{ ctx.session.locale }}">
{% block header %}
<div class="page-header">{% using "mm-sc-new-header-v5" %}</div>
{% endblock %}
<div class="page-main">
<div class="content">
{% block content %}
<div class="page-root" id="root"></div>
<script>
window._PAGE_DATA_ = {{ pageData | default({}) | dump | replace(r/<\/script/ig, '<\\\/script') | safe }};
{% if pageConfig %}
window._PAGE_CONFIG_ = {{ pageConfig | default({}) | dump | safe }};
{% endif %}
</script>
{% endblock %}
</div>
</div>
</body>
</html>先返回 <head> 部分的内容,然后返回 <body> ,其中 <head> 只依赖静态资源版本,几乎不耗时,而 <body> 中依赖一些比较耗时的取数逻辑。要做的就是修改 admin 页面的 controller :
module.exports = app => class AdminController extends app.Controller {
async index() {
// 首先对用户进行鉴权
const previliges = await this.service.userInfo.checkPrevilige();
// 调用插件提供的 rende 方法
this.ctx.spark.render('admin/index.nj', {
// 要先返回 head 部分,所以正则需要匹配 head 紧跟着的第一个元素,也就是 <body
regList: [/<body data-spm="customize"/],
dataList: [
// 由于第一部分需要的数据是现成的,直接挂载在 ctx 上,所以直接传入就好了
this.ctx,
// 第二部分是复杂的取数逻辑,将取数的逻辑封装成一个异步方法传进来就好了
async () => getPageData.call(this),
],
});
async function getPageData() {
...耗时逻辑
const pageData = {
...
};
return mergerCommonContext({ pageData }, this.ctx);
}
}
};这样浏览器请求 admin 页面时,就会按照给定的正则对页面进行切分并流式返回了。
注意事项
- 一定要先对请求进行鉴权,然后再调用 render 方法,因为一旦页面开始返回,再进行鉴权动作就已经晚了;
总结
一开始对做这件事情没有很大的热情,但做出来之后只花了半天就在两个业务中成功接入落地,而且获得了页面性能的上升,结果还是很令我满意的。
本文发布于 2021年3月23日,最后更新于 2021年3月23日,距今已有 1913 天,文章内容可能已经过时。