
介绍
引用 MDN 的介绍:
IndexedDB 是一个事务型数据库系统,类似于基于 SQL 的 RDBMS。 然而不同的是它使用固定列表,IndexedDB 是一个基于 JavaScript 的面向对象的数据库。 IndexedDB 允许您存储和检索用键索引的对象; 可以存储 structured clone algorithm 支持的任何对象。 您只需要指定数据库模式,打开与数据库的连接,然后检索和更新一系列事务中的数据。
IndexedDB 是一种低级 API,用于客户端存储大量结构化数据(包括, 文件/ blobs)。该 API 使用索引来实现对该数据的高性能搜索。虽然 Web Storage 对于存储较少量的数据很有用,但对于存储更大量的结构化数据来说,这种方法不太有用。IndexedDB 提供了一个解决方案。
区别
这是我整理的 WebStorage 和 indexedDB 的之间区别,有问题的地方还请指出。 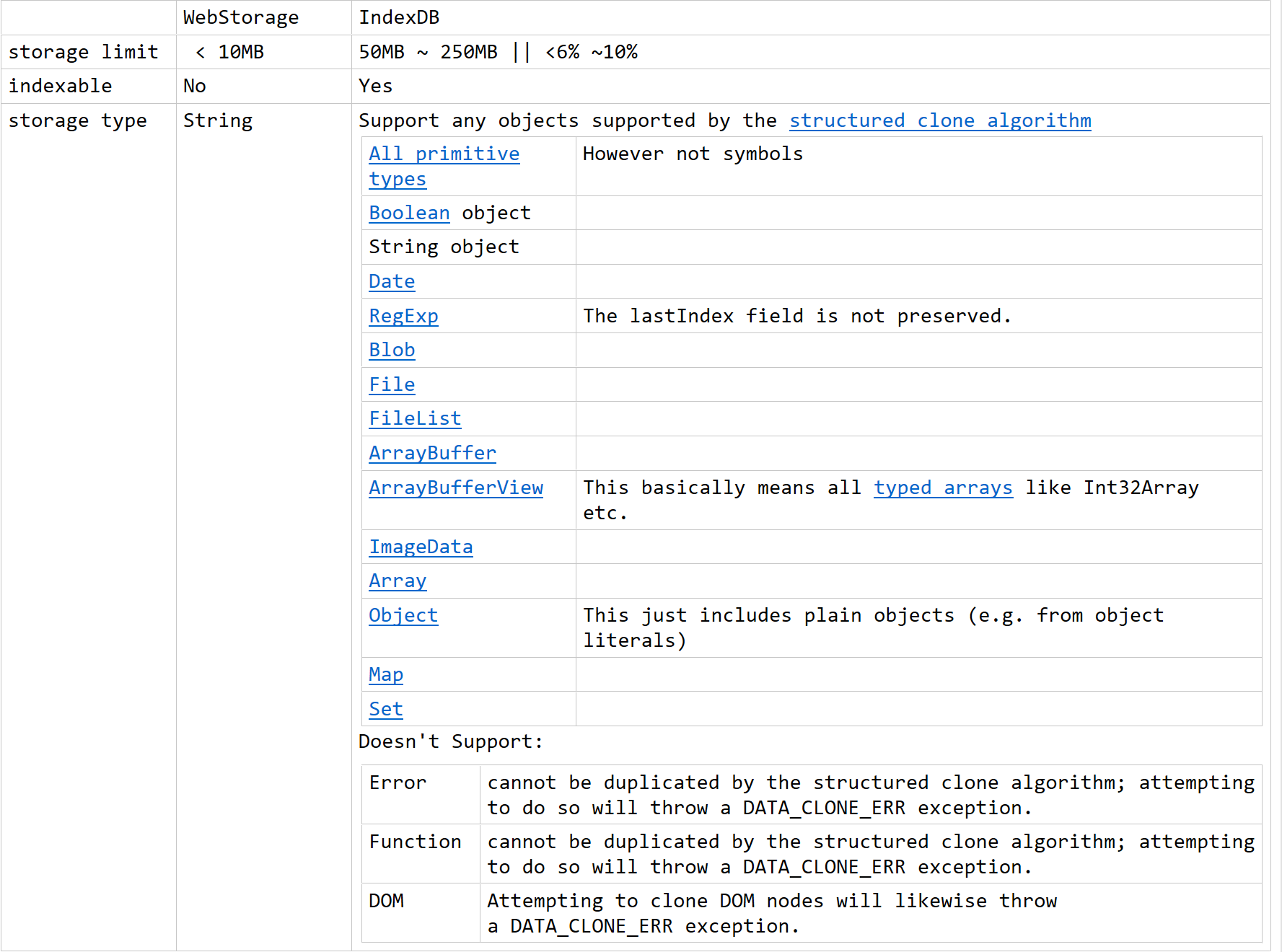
用法
1. 打开数据库
const DB_NAME = "Netease";
const DB_VERSION = 1;
const OB_NAMES = {
UseKeyPath: "UseKeyPath",
UseKeyGenerator: "UseKeyGenerator",
};
/**
* NOTE:
* 1. 第一次打开可能会提示用户获取 indexedDB 的权限
* 2. 浏览器隐身模式不会存在本地,只会存储在内存中
*/
const request = window.indexedDB.open(DB_NAME, DB_VERSION);indexedDB.open 接收两个参数,分别为数据库名称和版本,返回的是一个 IDBOpenDBRequest 对象。可以以 DOM 事件的方式监听它的 success 和 error 来获取到它的结果。几乎所有对 indexedDB 的异步操作都是这种以事件的方式进行,返回一个拥有结果或错误的 IDBRequest 对象。在这里,open 方法得到的结果是一个 IDBDatabase 的实例。
第二个参数是数据库的版本。版本决定了数据库的模式:存储在里面的 object store 和它们的结构。当第一次通过 open 方法打开数据库时,会触发一个 onupgradeneeded 事件,我们可以也只能在这里设置数据库模式。当数据库已经存在,而我们打开一个更高版本时,同样会触发 onupgradeneeded 事件,用来更新数据库模式。
添加处理方法
我们可以通过监听它的 success, error 以及 upgradeneeded 事件来做相应的操作。
request.onerror = function (event) {
// Do something with request.errorCode!
console.error("open request failed", event.target.error);
};
request.onsuccess = function (event) {
// Do something with request.result!
// console.log('open request success', event)
var db = event.target.result;
db.onerror = function (e) {
console.error("Database error: ", e.target.error);
};
db.onclose = (e) => {
console.error("Database close:", e.target.error);
};
};可以在 success 事件里面拿到 db 对象,这个是后续操作的主体。
错误处理
由于是基于 DOM 事件模式的,所以所有的错误是会冒泡的。也就是说在一个特定 request 的上引发的错误会依次冒泡到事务,然后到 db 对象。 如果为了简化错误处理,可以直接在 db 对象上添加错误处理:
db.onerror = function (e) {
// 可以处理这个数据库上所有的错误
console.error("Database error: ", e.target.error);
};2. 创建或更新数据库版本
前面已经说过,当创建或者增大数据库版本的时候,会触发 onupgradeneeded 事件。在事件内部,可以拿到 db 对象来创建或更新 object store , 具体如下。
request.onupgradeneeded = function (event) {
/**
* NOTE:
* 1. 创建新的 objectStore
* 2. 删除旧的不需要的 objectStore
* 3. 如果需要更新已有 objectStore 的结构,需要先删除原有的 objectStore ,然后重新创建
*/
// The IDBDatabase interface
console.log("onupgradeneeded", event);
var db = event.target.result; // Create an objectStore for this database
const objectStore = db.createObjectStore(OB_NAMES.UseKeyPath, {
keyPath: "time",
});
};3. 构建数据库
indexedDB 是以对象存储(object store)而不是以表结构存储的,一个数据库可以存储任意多个存储对象。每当有一个值存储在 object store 里面,就必须和一个 key 关联起来。有几种提供 key 的方法,取决于 object store 使用 key path 还是 key generator.
它们之间区别,借用 MDN 的一个表格来看一下:
| Key Path (keyPath) | Key Generator (autoIncrement) | Description |
|---|---|---|
| No | No | This object store can hold any kind of value, even primitive values like numbers and strings. You must supply a separate key argument whenever you want to add a new value. |
| Yes | No | This object store can only hold JavaScript objects. The objects must have a property with the same name as the key path. |
| No | Yes | This object store can hold any kind of value. The key is generated for you automatically, or you can supply a separate key argument if you want to use a specific key. |
| Yes | Yes | This object store can only hold JavaScript objects. Usually a key is generated and the value of the generated key is stored in the object in a property with the same name as the key path. However, if such a property already exists, the value of that property is used as key rather than generating a new key. |
来自 https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API/Using_IndexedDB
当存储的是不是基础类型而是 js 对象的时候,我们还可以给 object store 创建索引,这样就可以通过索引属性来查找某一个具体的对象。而且, 索引还能再一定程度上约束要存储的对象。当创建索引的时候通过设置唯一标识,可以确保不会存储拥有两个相同索引值的对象。 看一个例子,假设我们有如下日志数据需要存储:
const TestData = [
{
event: "NE-TEST1",
level: "warning",
errorCode: 200,
url: "http://www.example.com",
time: "2017/11/8 下午4:53:039",
isUploaded: false,
},
{
event: "NE-TEST2",
msg: "测试2",
level: "error",
errorCode: 1000,
url: "http://www.example.com",
time: "2017/11/8 下午4:53:042",
isUploaded: false,
},
{
event: "NE-TEST3",
msg: "测试3",
level: "info",
errorCode: 3000,
url: "http://www.example.com",
time: "2017/11/8 下午4:53:043",
isUploaded: false,
},
{
event: "NE-TEST4",
mgs: "测试4",
level: "info",
url: "http://www.example.com",
time: "2017/11/8 下午4:53:0423",
isUploaded: false,
},
];这里有两种存储方式,分别是通过 key path 和 key generator.
function obUseKeypath(db) {
const objectStore = db.createObjectStore(OB_NAMES.UseKeyPath, {
keyPath: "time",
});
objectStore.createIndex("errorCode", "errorCode", { unique: false });
objectStore.createIndex("level", "level", { unique: false });
}
function obUseKeyGenerator(db) {
const objectStore = db.createObjectStore(OB_NAMES.UseKeyGenerator, {
autoIncrement: true,
});
objectStore.createIndex("errorCode", "errorCode", { unique: false });
objectStore.createIndex("time", "time", { unique: true });
objectStore.createIndex("level", "level", { unique: false });
}4. 增删改查
为了方便介绍这部分的内容,我们先把上一节的代码包装一下,为了方便后续例子的讲解:
function openindexedDB() {
// The call to the open() function returns an IDBOpenDBRequest object with a result (success) or error value that you handle as an event.
return new Promise((resolve, reject) => {
/**
* NOTE:
* 1. 第一次打开可能会提示用户获取 indexedDB 的权限
* 2. 浏览器隐身模式不会存在本地,只会存储在内存中
*/
const request = window.indexedDB.open(DB_NAME, DB_VERSION);
request.onerror = function (event) {
// Do something with request.errorCode!
console.log("open request failed", event);
console.error(event.target.error);
};
request.onsuccess = function (event) {
// Do something with request.result!
// console.log('open request success', event)
var db = event.target.result;
db.onerror = function (e) {
console.error("Database error: ", e.target.error);
reject(e.target.error);
};
db.onclose = (e) => {
console.error("Database close:", e.target.error);
reject(e.target.error);
};
resolve(db);
};
request.onupgradeneeded = function (event) {
/**
* NOTE:
* 1. 创建新的 objectStore
* 2. 删除旧的不需要的 objectStore
* 3. 如果需要更新已有 objectStore 的结构,需要先删除原有的 objectStore ,然后重新创建
*/
// The IDBDatabase interface
console.log("onupgradeneeded", event);
var db = event.target.result; // Create an objectStore for this database
obUseKeypath(db);
obUseKeyGenerator(db);
/**
* NOTE:
* transaction
* 三个事件:
* 1. error
* 2. abort
* 3. complete
* 两个方法:
* 1. abort
* Rolls back all the changes to objects in the database associated with this transaction. If this transaction has been aborted or completed, then this method throws an error event.
* 2. objectStore
* Returns an IDBObjectStore object representing an object store that is part of the scope of this transaction.
*/
db.transaction.oncomplete = function (e) {
console.log("obj create success", e);
};
};
});
}
function obUseKeypath(db) {
const objectStore = db.createObjectStore(OB_NAMES.UseKeyPath, {
keyPath: "time",
});
objectStore.createIndex("errorCode", "errorCode", { unique: false });
objectStore.createIndex("level", "level", { unique: false });
}
function obUseKeyGenerator(db) {
const objectStore = db.createObjectStore(OB_NAMES.UseKeyGenerator, {
autoIncrement: true,
});
objectStore.createIndex("errorCode", "errorCode", { unique: false });
objectStore.createIndex("time", "time", { unique: true });
objectStore.createIndex("level", "level", { unique: false });
}这样每次我们需要对数据库做操作的话只需要调用 openindexedDB 方法就可以了。
事务
所有对数据库的操作都是建立在事务(transaction)上的,有三种模式(mode):readonly, readewrite, versionchange. 要修改数据库结构的 schema ,必须在 versionchange 模式下。读取和修改对应另外两种模式。 通过 IDBDatabase.transaction 打开一个 transaction, 接收两个参数:storeNames, mode. 所有对数据库的操作都遵循以下流程:
- Get database object
- Open transaction on database
- Open object store on transaction
- Perform operation on object store
加速事务操作:
- 当定义作用域时(scope), 只定义需要的 object stores. 这样,就可以在不重叠的作用域上并行的执行多个事务。
- 只有在需要的时候才开启一个 readwrite 事务。因为在重叠的作用域上可以并发执行多个 readonly 事务,但只能有一个 readwrite 事务。
增
方法如下:
- 首先拿到 db 对象
- 然后打开一个
readwrite事务 - 通过事务拿到 object store 对象
- 执行添加数据操作
/**
* 添加数据
* @param {array} docs 要添加数据
* @param {string} objName 仓库名称
*/
function addData(docs, objName) {
if (!(docs && docs.length)) {
throw new Error("docs must be a array!");
}
return openindexedDB().then((db) => {
const tx = db.transaction([objName], "readwrite");
tx.oncomplete = (e) => {
console.log("tx:addData onsuccess", e);
return Promise.resolve(docs);
};
tx.onerror = (e) => {
e.stopPropagation();
console.error("tx:addData onerror", e.target.error);
return Promise.reject(e.target.error);
};
tx.onabort = (e) => {
console.warn("tx:addData abort", e.target);
return Promise.reject(e.target.error);
};
const obj = tx.objectStore(objName);
docs.forEach((doc) => {
const req = obj.add(doc);
/**
* NOTE:
* request
* 两个事件:
* 1. success
* 2. error
*/ // req.onsuccess = e => console.log('obj:addData onsuccess', e.target)
req.onerror = (e) => {
console.error("obj:addData onerror", e.target.error);
};
});
});
}如果要把上面的 TestData 同时使用 key generator 和 key path 方式保存到数据库中,那么方法:
addData(TestData, OB_NAMES.UseKeyGenerator).then(() =>
addData(TestData, OB_NAMES.UseKeyPath),
);删
流程和添加一样:
/**
* 删除指定 key 的数据
* @param {string} objName 仓库名称
* @param {*} key 要删除数据的 primary key 值
*/
function deleteData(objName, key) {
return openindexedDB().then((db) => {
const tx = db.transaction([objName], "readwrite");
const obj = tx.objectStore(objName);
const req = obj.delete(key);
req.onsuccess = (e) => {
console.log(`readData success. key:${key},result:`, e.target.result);
return Promise.resolve(e.target.result);
};
req.onerror = (e) => {
console.error(`readData error. key:${key},error: ${e.target.errorCode}`);
return Promise.reject(e.target.error);
};
});
}假如要删除 UserKeyGenerator 里 key 为 1 值,那么:
deleteData(OB_NAMES.UseKeyGenerator, 1).then((doc) => console.log(doc));查
方法:
/**
* 读取给定 key 的数据
* @param {string} objName 仓库名称
* @param {*} key 要读取数据的 primary key 值
*/
function readData(objName, key) {
return openindexedDB().then((db) => {
const tx = db.transaction([objName]);
const obj = tx.objectStore(objName);
const req = obj.get(key);
req.onsuccess = (e) => {
console.log(`readData success. key:${key},result:`, e.target.result);
return Promise.resolve(e.target.result);
};
req.onerror = (e) => {
console.error(`readData error. key:${key},error: ${e.target.errorCode}`);
return Promise.reject(e.target.error);
};
});
}例子:
readData(OB_NAMES.UseKeyGenerator, 1);改
方法:
/**
* 更新指定 key 的数据
* @param {string} objName 仓库名称
* @param {*} key 指定的 key
* @param {object} changes 要修改的属性值
*/
function updateData(objName, key, changes) {
return openindexedDB().then((db) => {
return new Promise((resolve, reject) => {
const tx = db.transaction([objName], "readwrite");
const obj = tx.objectStore(objName);
const req = obj.get(key);
req.onsuccess = (e) => {
let doc = e.target.result;
let newDoc = Object.assign(doc, changes);
const req = obj.put(newDoc);
req.onsuccess = (e) => {
console.log(`updateData success, newDoc:`, newDoc, e);
resolve(e.target.result);
};
req.onerror = (e) => {
resolve(e.target.result);
};
};
req.onerror = (e) => {
reject(e.target.error);
};
});
});
}例子:
updateData(OB_NAMES.UseKeyGenerator, 1, { time: "123" })
.then((doc) => console.log(doc))
.catch(console.error);使用游标 (cursor)
使用 get 方法需要预先知道一个 key. 如果需要步进整个 object store 的值,那么可以使用 cursor.
/**
* 通过 cursor 获取制定仓库下的所有数据
* @param {string} objName 仓库名称
* @param {function} [cb] 回调函数,对每次得到的 cursor 进行操作
* @returns {Promise.<array.<object>} 包含所有数据的数组
*/
function getAllByCursor(objName, cb) {
return openindexedDB().then((db) => {
const arr = [];
const tx = db.transaction([objName]);
const obj = tx.objectStore(objName);
return new Promise((resolve) => {
obj.openCursor().onsuccess = (e) => {
const cursor = e.target.result;
if (cursor) {
arr.push(cursor.value);
cb && cb(cursor);
cursor.continue();
} else {
return resolve(arr);
}
};
});
});
}openCursor() 方法接收多个参数。
- 第一个参数,可以传入一个 key range 对象来限制需要获取值的范围。
- 第二个参数,可以设置迭代的方向。
成功回调函数的 result 值就是 cursor 本身,当前遍历值可以通过 cursor 对象的 key 和 value 值获取。如果要继续往下遍历,那么调用 cursor 的 continue() 方法,当遍历结束时, cursor 也就是 event.target.result 的值为 undefined. 如果要获取 UseKeyGenerator 仓库下所有的值,那么可以这样:
getAllByCursor(OB_NAMES.UseKeyGenerator).then(console.log);除了 openCursor() 外,还可以使用 openKeyCursor() 来获取所有存储对象的主键值,使用方法和 openCursor 一样,
使用索引 (index)
在建立 object store 时,如果我们给它创建了索引。这时,就可以使用索引来查找某个特定属性的值:
function getByIndex(objName, indexName, key) {
return openindexedDB().then((db) => {
const index = db.transaction(objName).objectStore(objName).index(indexName);
return new Promise((resolve) => {
index.get(key).onsuccess = (e) => {
console.log("getByIndex", e.target.result);
return resolve(e.target.result);
};
});
});
}比如,我们要查找 level 为 info 的日志,那么可以这样:
getByIndex(OB_NAMES.UseKeyGenerator, "level", "info").then((doc) =>
console.log(doc),
);设置范围 (range) 和游标 (cursors) 的方向
如果需要设置 cursor 遍历的范围,可以使用 IDBKeyRange 对象并把作为第一个参数给 openCursor() 或者 openKeyCursor() . 一个 key range 的值,可以认为是一个区间,区间的类型可以是开区间也可以是闭区间。看一些例子:
/**
* NOTE:
* 只包括给定的值
*/
getWithRangeByCursor(
OB_NAMES.UseKeyGenerator,
"errorCode",
IDBKeyRange.only(1000),
)
.then(console.log)
.catch(console.error);
/**
* NOTE:
* 默认是闭区间
*/
getWithRangeByCursor(
OB_NAMES.UseKeyGenerator,
"errorCode",
IDBKeyRange.lowerBound(1000),
)
.then(console.log)
.catch(console.error);
/**
* NOTE:
* 设置第二个可选参数为 true,则为开区间
*/
getWithRangeByCursor(
OB_NAMES.UseKeyGenerator,
"errorCode",
IDBKeyRange.lowerBound(1000, true),
)
.then(console.log)
.catch(console.error);
/**
* NOTE:
* 闭区间,如果索引是数字,那么按照数字大小决定升序
*/
getWithRangeByCursor(
OB_NAMES.UseKeyGenerator,
"errorCode",
IDBKeyRange.bound(1000, 2000),
)
.then(console.log)
.catch(console.error);
/**
* NOTE:
* 左闭右开区间:如果索引是字符串,那么安装 array.sort() 的方式决定升序
*/
getWithRangeByCursor(
OB_NAMES.UseKeyGenerator,
"time",
IDBKeyRange.bound(
"2017/11/8 下午4:53:042",
"2017/11/8 下午4:53:043",
false,
true,
),
)
.then(console.log)
.catch(console.error);降序迭代
默认情况下,迭代的方向是升序的。如果需要按照降序规则迭代,那么只要把 prev 作为 openCursor() 的第二个参数就可以了:
getWithDescendingByCursor(OB_NAMES.UseKeyGenerator, "time")
.then(console.log)
.catch(console.error);本文发布于 2017年12月6日,最后更新于 2017年12月6日,距今已有 3116 天,文章内容可能已经过时。